한글폰트 적용 - 코랩
!sudo apt-get install -y fonts-nanum
!sudo fc-cache -fv
!rm ~/.cache/matplotlib -rf
Fixed Random Seed
seed 값에 의해 동일한 코드를 사용해도 결과가 다를 수 있기에, 동일한 결과를 위해 seed값을 고정시킵니다.
import numpy as np
import random
import os
def seed_everything(seed):
random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
np.random.seed(seed)
seed_everything(42) # Seed 고정
데이터 불러오기 및 확인
import pandas as pd
train_df = pd.read_csv('/content/sample_data/train.csv')
test_df = pd.read_csv('/content/sample_data/test.csv')
display(train_df.head(3))
display(test_df.head(3))
EDA
범주형 변수 확인
# 시각화 패키지 불러오기
import seaborn as sns
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
# 한글 폰트 설정하기
fe = fm.FontEntry(fname = 'MaruBuri-Regular.otf', name = 'MaruBuri')
fm.fontManager.ttflist.insert(0, fe)
plt.rc('font', family='NanumBarunGothic')
fig, axes = plt.subplots(2, 2, figsize=(25,10)) # 2x2 형식으로 4개 그래프 동시에 표시
sns.countplot(x = train_df['대출기간'], ax=axes[0][0]).set_title('대출기간')
sns.countplot(x = train_df['근로기간'], ax=axes[0][1]).set_title('근로기간')
sns.countplot(x = train_df['주택소유상태'], ax=axes[1][0]).set_title('주택소유상태')
sns.countplot(x = train_df['대출목적'], ax=axes[1][1]).set_title('대출목적')
plt.show()
근로기간에서 < 1 year이랑 <1 year이 있는걸 확인했습니다.
둘 다 똑같은 의미를 취하는 것이기에 같게 만들어주는 작업이 필요할 듯 합니다.
그런데 근로기간의 데이터를 다시 한번 살펴보니 year에 3이 들어가있는걸 확인했고 10+ year, 1year도 중복이 되기에 마찬가지로 바꿔줍니다.
fig, axes = plt.subplots(2, 2, figsize=(25,10)) # 2x2 형식으로 4개 그래프 동시에 표시
sns.countplot(x = train_df['대출기간'], ax=axes[0][0]).set_title('대출기간')
sns.countplot(x = train_df['근로기간'], ax=axes[0][1]).set_title('근로기간')
sns.countplot(x = train_df['주택소유상태'], ax=axes[1][0]).set_title('주택소유상태')
sns.countplot(x = train_df['대출목적'], ax=axes[1][1]).set_title('대출목적')
plt.show()
다시 확인해주면 잘 처리된걸 확인할 수 있습니다.
세분화된 변수형 찾기
# '범주형 변수 찾기'
numeric_columns = train_df.select_dtypes(include=['number'])
categorical_col_names = train_df.select_dtypes(include=['object']).columns.tolist()
# '범주형 변수 정보 확인하기'
summary = {}
unique_counts = {}
for col in categorical_col_names:
summary[col] = train_df[col].value_counts().to_dict()
unique_counts[col] = train_df[col].nunique()
print(unique_counts)
범주형 변수의 경우 범주가 너무 세분화되어 있을 경우, One-Hot Encoding시 차원의 저주에 빠지기 쉽습니다. 따라서 너무 세분화된 범주형 변수를 제거해주기로 결정합니다.
따라서 ID를 제거해줍니다.
EDA: 수치형 변수 확인하기
결측치 확인
numeric_columns_train = train_df.select_dtypes(include=['number'])
numeric_columns_test = test_df.select_dtypes(include=['number'])
null_tot_train = numeric_columns_train.isnull().sum()
null_tot_test = numeric_columns_test.isnull().sum()
print(null_tot_train)
print(null_tot_test)
Describe & info
numeric_columns_train.describe()
부채_대비_소득_비율: max가 9999인게 조금 이상합니다.
총계좌수: max가 169인게 이상합니다.
최근_2년간_연체_횟수: max가 30번인게 이상합니다.
연간소득: 0인데 대출이 가능했는지 의문이 듭니다.
min_income = train_df['연간소득'].min()
rows_with_min_income = train_df[train_df['연간소득'] == min_income]
rows_with_min_income
부채_대비_소득_비율의 값이 9999인 것과 연간소득 0인데이터가 중복되는걸 확인할 수 있습니다.
이 데이터는 모델을 학습시킬 때 좋지 않다고 판단하여 제거하기로 결정했습니다.
수치형 변수 시각화
# 수치형 변수들을 시각화 (예: 히스토그램)
numeric_columns_train.hist(bins=10, figsize=(10, 6))
plt.suptitle('Numeric Variables Distribution')
plt.show()
대출금액을 제외하고 대부분의 데이터들이 좌측편향돼있다는 걸 확인할 수 있습니다.
이걸 로그변환시킬지 아니면 이상치의 값들을 제거해야할지 결정을 해줘야할 듯합니다.
그러나 저는 로그변환을 시도한 데이터가 좋지 않은 예측값을 냈기에 이상치의 값들을 일부분 제거하여 모델을 학습시키는게 좋을 듯 합니다.
데이터 전처리 1: 학습 및 추론 데이터 설정
제출을 위한 코드와 제가 확인할 코드를 나눠서 진행하였습니다.
from sklearn.model_selection import train_test_split
X = train_df.drop(columns=['ID', '근로기간','대출등급'])
y = train_df['대출등급']train_x = train_df.drop(columns=['ID', '근로기간', '대출등급'])
train_y = train_df['대출등급']
test_x = test_df.drop(columns=['ID', '근로기간'])X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, stratify=y, random_state=42)데이터 전처리 2: 범주형 변수 수치화
LabelEncoder를 통해 범주형 변수 수치화를 진행합니다.
from sklearn.preprocessing import LabelEncoder
categorical_features = ['대출기간', '주택소유상태', '대출목적']
for i in categorical_features:
le = LabelEncoder()
le=le.fit(train_x[i])
le=le.fit(X[i])
train_x[i]=le.transform(train_x[i])
X[i]=le.transform(X[i])
for case in np.unique(test_x[i]):
if case not in le.classes_:
le.classes_ = np.append(le.classes_, case)
test_x[i]=le.transform(test_x[i])
display(train_x.head(3))
display(test_x.head(3))
모델 선정 및 학습
RandomForestClassifier
from sklearn.ensemble import RandomForestClassifier
RFC = RandomForestClassifier()
RFC.fit(X_train, y_train)max_depth_list = range(20,25)
accuracy = []
for m in max_depth_list:
RFC = RandomForestClassifier(random_state = 42, max_depth = m)
RFC.fit(X_train, y_train)
pred = RFC.predict(X_test)
score = accuracy_score(pred, y_test)
accuracy.append(score)
plt.plot(max_depth_list, accuracy)
plt.xlabel('max_depth')
plt.ylabel('accuracy')
plt.show()
from sklearn.metrics import accuracy_score
pred = RFC.predict(X_test)
score = accuracy_score(pred, y_test)
print(f"정확도: {score}")가장 잘 나온 max_depth의 값을 선택하여 예측한 결과 정확도는 0.8231이 나왔습니다.
DecisionTreeClassifier
DT = DecisionTreeClassifier(random_state = 42, criterion = 'entropy', max_depth = 5)
DT.fit(X_train, y_train)max_depth_list = range(1,101)
accuracy = []
for m in max_depth_list:
DT = DecisionTreeClassifier(random_state = 42, criterion = 'entropy', max_depth = m)
DT.fit(X_train, y_train)
pred = DT.predict(X_test)
score = accuracy_score(pred, y_test)
accuracy.append(score)
plt.plot(max_depth_list, accuracy)
plt.xlabel('max_depth')
plt.ylabel('accuracy')
plt.show()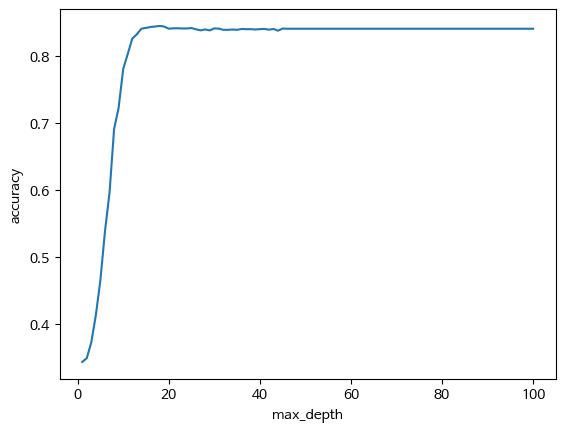

DT = DecisionTreeClassifier(random_state = 42, criterion = 'entropy', max_depth = 19)
DT.fit(train_x, train_y)
가장 잘 나온 max_depth로 학습시켜줍니다.
KNeighborsClassifier
n_neighbors_list = range(1,10)
accuracy = []
for m in n_neighbors_list:
KNN = KNeighborsClassifier(n_neighbors = m)
KNN.fit(X_train, y_train)
pred = KNN.predict(X_test)
score = accuracy_score(pred, y_test)
accuracy.append(score)
plt.plot(n_neighbors_list, accuracy)
plt.xlabel('n_neighors')
plt.ylabel('accuracy')
plt.show()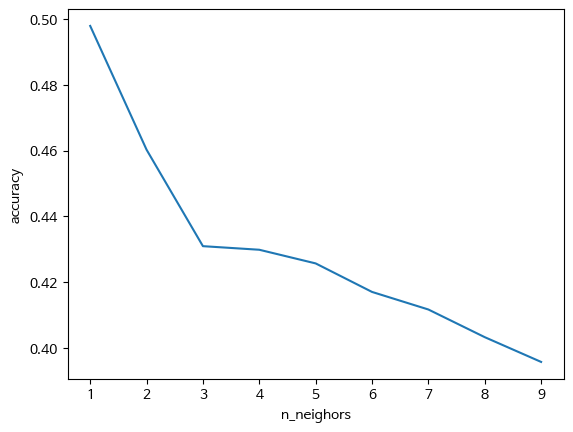
정확도가 앞서 실행한 두 모델에 비해 현저하게 낮기에 이 모델은 채택안하기로 결정합니다.
그래서 예측을 수행하여 데이콘 대회에 제출한 결과
0.79의 정확도를 얻었습니다.
처음으로 대회에 참여하여서 이정도면 나쁘지 않은 결과라고 생각합니다.
앞으로 더욱 정진하겠습니다!
'프로그래밍 > 프로젝트' 카테고리의 다른 글
| ARIMA 모델 검증 및 예측 정확도 평가 (0) | 2024.05.21 |
|---|---|
| ARIMA 모델 (0) | 2024.05.21 |
| 고객 유지를 위한 필요한 행동 예측 (1) | 2024.01.14 |
| 원본 데이터 보존 (0) | 2023.11.28 |
| 머신러닝 기초 및 순서 (0) | 2023.11.21 |