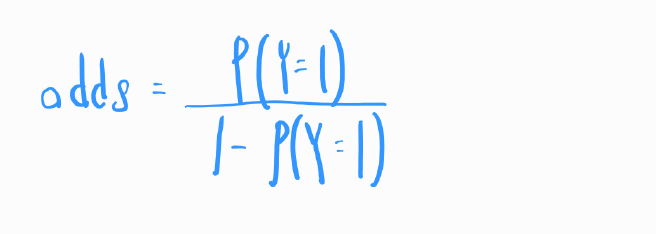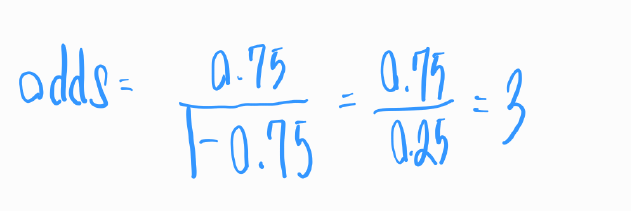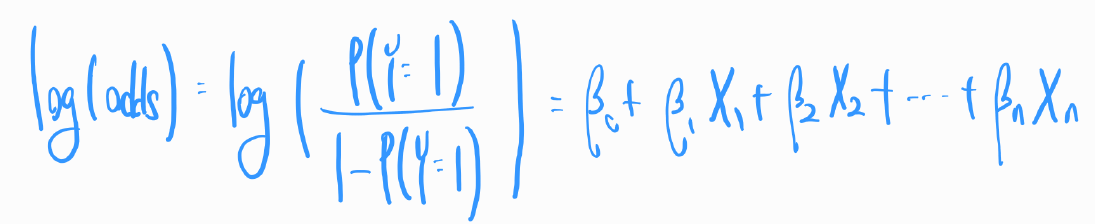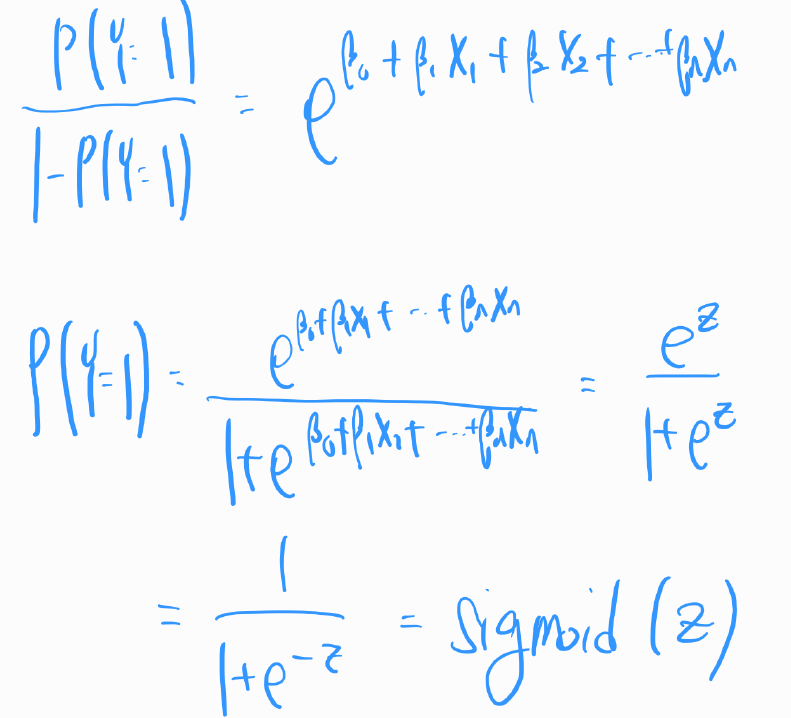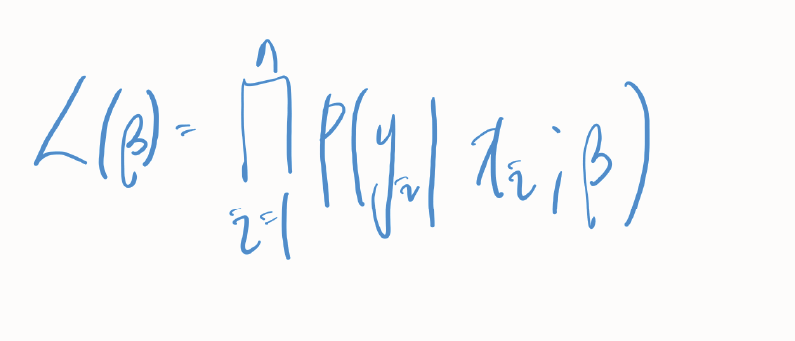학교에서 수업 시간에 공모전에 참여하여 개개인마다의 인사이트를 얻고 발표를 하라는 교수님의 지시에 공모전을 찾아보다가 한 팀원이 '여기에 참여해보자!' 하여 24년 홍천군 공모전에 참여하게 되었습니다.
참가하게 된 계기나 목표가 있었나요?
기왕 참가하게 된 거 상은 무조건 타고 간다는 마인드였습니다. '세상은 2등은 기억해주지 않기 때문에 1등 해보자라는 마음가짐'이였습니다.
2. 준비 과정
어떤 방식으로 준비했나요? (팀원 구성, 역할 분배, 공부 방법 등)
팀원들 중 2명은 서류 작성에 많은 도움을 주셨고, 저랑 다른 팀원 한 명은 전반적인 데이터를 분석하는 역할을 맡았습니다. 여타 다른 공모전들도 마찬가지로 공모전은 얼마나 진심으로 문제에 대해 고민했고 그것의 해결방안을 어떻게 잘 ppt에 녹여내는지가 관건이기에 문제를 잘 설정하는 것에 진심이였던 것 같습니다.
어려웠던 점과 이를 어떻게 해결했나요?
저희는 최적의 위치 선정과 관련된 프로젝트를 진행했는데 여기서 유클리디안 거리를 사용했을 때는 지형물, 건물과 같은 장애물을 제외하고 오로지 직선 거리만을 계산하기에 최적의 위치를 적절하게 선정하는데에 있어서 어려움이 있었습니다. 고민을 하던 와중 같이 데이터 분석 역할을 맡은 팀원 한 명이 '네이버 길찾기의 최소 경로를 사용하면 어떨까'라는 말을 해줬고, 이것이 저희가 가지고 있는 한계를 돌파해 줄 수 있는 key라는 느낌이 와 바로 진행하니 좋은 결과를 얻을 수 있었습니다.
3. 공모전 진행 중 경험
공모전에서 겪은 인상 깊은 경험이 있나요?
사실 팀원들과 이렇게 호흡이 잘 맞고 좋은 사람들이랑 했던 기억이 많이 없어서.. 좋은 사람들과 힘든 시간을 극복해가면서 같이 성장하는 느낌을 받았던 게 참 좋았던 것 같습니다.
예상과 달랐던 점이 있었나요?
23년도에 했던 데이터 분석은 팀원들이 데이터 분석에 대해 관심없기도 했고 잘 몰라서 대충해서 그냥 혼자 다 했었는데 이번에도 그런 팀원이 있었기는 했지만 자신의 힘이 되는 한에서 끝까지 도와줄려고 하는 모습에서 감동?을 받았었고, 같이 데이터 분석을 하는 친구는 밤을 새가며 자신의 책임을 다 하는거에서 이 친구들이랑 더 많은 공모전이나 프로젝트 할 수 있었으면 좋겠다라고 생각했습니다.
4. 결과 및 배운 점
공모전 결과(수상 여부와 관계없이) 어떤 점에서 성장했나요?
음... 일단 최우수상! 1등했고, 힘든 시간 동안 같이 버텨준 팀원들이 가장 자랑스럽고, 팀장인 제가 역량이 부족했다고 생각했는데, 잘 따라주기도 했고 많은 도움을 받았습니다. 지금 팀장으로서 어떤 부분이 제가 부족한 지를 알게 된 거 같아 좋았습니다.
어떤 기술이나 역량이 향상되었나요?
공부의 본질을 알게 되었다고 해야하나..ㅋㅋㅋ 모르는게 있으면 가만히 있는게 아니라 고민하고 찾고 또 찾으면 결국 자신만의 답이 나온다? 그게 정답은 아니더라도 자신만의 답을 그렇게 많이 도출하다 보면 결국에는 근접할 수 있습니다. 결론은 탐구하고 인내하는 능력이 늘어난 것 같습니다.
5. 소감 및 앞으로의 계획
이번 경험이 앞으로 어떤 영향을 줄 것 같나요?
도전 = 두려움이 아니라 도전 = 성장 이라고 생각을 하면서 앞으로 살아가도록 도움을 준 것 같네요
다음에는 어떤 공모전에 도전하고 싶은가요?
공모전보다 학회나 학술대회를 많이 참여하려고요. 이번 공모전하면서 제 수학적 식견이 낮아 논문의 수식을 이해못했던 적이 있어서 부끄럽더라고요. 네. 그래서 학회나 학술대회에 많이 참여할 것 같습니다.
시계열 데이터 전처리에 있어 핵심적인 역할을 하는데, 시계열 데이터 분석은 시간의 흐름에 따른 패턴을 찾는 과정이기 때문에, 날짜와 시간을 다루는 것은 필수적입니다.
datetime 모듈은 다음과 같은 주요 클래스를 제공합니다.
datetime.datetime:
날짜와 시간을 모두 포함하는 클래스입니다. 특정 날짜와 시간을 생성하고, 두 datetime 객체 간의 차이를 계산하거나, 날짜와 시간을 포맷팅하는데 사용됩니다.
datetime.date:
날짜만을 포함하는 클래스입니다. 연도, 월, 일 정보를 다루며, 날짜 간의 차이를 계산할 수 있습니다.
datetime.time:
시간만을 포함하는 클래스입니다. 시, 분, 초, 마이크로초 정보를 다룹니다.
datetime.timedelta:
두 datetime 객체 간의 차이를 나타내는 클래스입니다. 시간 간격을 계산하고, 날짜와 시간에 간격을 더하거나 뺄 수 있습니다.
문자열을 datetime 객체로 변환: 데이터셋에서 날짜와 시간이 문자열로 저장된 경우, 이를 datetime 객체로 변환하여 다양한 시간 연산을 수행할 수 있습니다.
시간 간격 계산: 두 사건 사이의 시간 간격을 계산하여 분석에 활용할 수 있습니다.
날짜/시간 정규화: 날짜와 시간을 표준 형식으로 변환하여 일관된 데이터 처리를 할 수 있습니다.
특정 시점 추출: 월말, 분기말 등의 특정 시점을 추출하여 분석할 수 있습니다.
시간 기반 특성 생성: 요일, 월, 분기 등의 시간 기반 특성을 생성하여 모델링에 활용할 수 있습니다.
적용
현재 날짜와 시간 가져오기
now = datetime.now()
time delta 클래스를 이용한 날짜 연산
future_date = now + timedelta(days=100)
timedelta 클래스는 기간을 표현하며, 날짜나 시간에 더하거나 빼는 연산에 사용됩니다. 예를 들어, 100일 후의 날짜를 계산하려면 timedelta(days = 100)를 현재 날짜에 더해주면 됩니다.
날짜만 추출
future_data_only = future_date.date()
경우에 따라 시간 부분을 제외하고 날짜만 필요할 수 있습니다. 이때는 datetime객체의 .date() 메서드를 사용하여 날짜 부분만 추출할 수 있습니다.
시간 차이 측정
from datetime import datetime, timedelta
# 현재 날짜와 시간
now = datetime.now()
# 100일 뒤의 날짜 계산
n_days = 100
future_date = now + timedelta(days = n_days)
# 두 날짜 사이의 차이 계산
time_diff = future_date - now
print(f"{n_days}일 뒤까지의 시간 차이: {time_diff}")
# 시간 단위로 변환
hours_diff = time_diff.total_seconds() / 3600print(f"시간 차이 (시간 단위로): {hours_diff:.2f} 시간")
# 과거 날짜 계산 (예: 어제)
yesterday = now - timedelta(days = 1)
print(f"어제 날짜와 시간: {yesterday}")
timedelta객체를 사용하여 미래 날짜를 계산하려면, 현재 날짜에timedelta(days=n_days)를 더해줍니다.
두 날짜의 차이를 계산할 때는datetime객체끼리의 뺄셈을 사용합니다. 이로 인해 또 다른timedelta객체가 생성됩니다.
timedelta객체의 전체 초(second)를 계산하려면total_seconds()메서드를 사용하고, 이를 시간 단위로 변환하려면 3600으로 나눕니다. total_seconds(): 전체 시간을 초 단위로 반환
과거 날짜를 계산하려면 현재 날짜에서timedelta(days=1)을 빼줍니다. days: 일 단위 차이 seconds: 초 단위 차이(일 단위를 제외한 초) microseconds: 마이크로초 단위 차이(초 단위를 제외한 마이크로초)
datetime의 date 클래스 생성과 날짜 비교
from datetime import date
# 오늘 날짜 가져오기
today = date.today()
print(f"오늘 날짜: {today}")
# 특정 날짜 설정
special_day = date(2024, 12, 25)
print(f"특별한 날: {special_day}")
# 날짜 비교if today < special_day:
print("특별한 날이 아직 오지 않았습니다.")
elif today == special_day:
print("오늘은 특별한 날입니다!")
else:
print("특별한 날이 지났습니다.")
특정 날짜를 설정할 때date(연도, 월, 일)형태로 작성합니다. 예를 들어,special_day = date(2024, 12, 25)와 같이 설정합니다.
datetime의 time 클래스 생성과 시간 비교
from datetime import datetime, time
# 현재 시간 가져오기
now = datetime.now()
current_time = now.time()
print(f"현재 시간: {current_time}")
# 특정 시간 설정
start_time = time(9, 0)
end_time = time(17, 0)
print(f"업무 시작 시간: {start_time}, 종료 시간: {end_time}")
# 시간 비교if start_time <= current_time <= end_time:
print("현재는 업무 시간입니다.")
else:
print("현재는 업무 시간이 아닙니다.")
특정 시간을 설정하려면time(시, 분)형태로 작성합니다. 예를 들어,start_time = time(9, 0)과end_time = time(17, 0)를 설정합니다.
datetime의 date와 time 결합하여 datetime 생성
from datetime import datetime, date, time
# 특정 날짜와 시간 설정
meeting_date = date(2024, 1, 15)
meeting_time = time(14, 30)
# 날짜와 시간을 결합하여 datetime 객체 생성
meeting_datetime = datetime.combine(meeting_date, meeting_time)
print(f"회의 일시: {meeting_datetime}")
datetime 객체를 생성하기 위해 datetime.combine() 메서드를 사용합니다. 이 메서드는 특정 날짜(date 객체)와 시간(time 객체)를 결합하여 datetime 객체를 만듭니다.
날짜 포맷팅: strftime을 활용한 날짜 및 시간 형식 지정
from datetime import datetime
# 현재 시간 얻기
now = datetime.now()
# 기본 포맷으로 출력 (예시: 2024-08-07 05:40:28)
basic_format = now.strftime('%Y-%m-%d %H:%M:%S')
print(f"기본 포맷: {basic_format}")
# 한글 포맷으로 출력 (예시: 2024년 08월 07일 05시 40분 28초)
korean_format = now.strftime('%Y년 %m월 %d일 %H시 %M분 %S초')
print(f"한글 포맷: {korean_format}")
# 날짜만 출력 (예시: 2024/08/07)
date_only_format = now.strftime('%Y/%m/%d')
print(f"날짜만: {date_only_format}")
# 12시간제 시간만 출력 (예시: 05:40 AM)
time_12h_format = now.strftime('%I:%M %p')
print(f"12시간제 시간만: {time_12h_format}")
# 요일과 월 이름 포함 포맷 (예시: Wednesday, 07 August 2024)
weekday_month_format = now.strftime('%A, %d %B %Y')
print(f"요일과 월 이름 포함 포맷: {weekday_month_format}")
# ISO 8601 표준 포맷 (예시: 2024-08-07T05:40:28)
iso_format_basic = now.strftime('%Y-%m-%dT%H:%M:%S')
print(f"ISO 8601 표준 포맷 (기본): {iso_format_basic}")
# ISO 8601 표준 포맷 (예시: 2024-08-07T05:40:28+0900)# 시간대 포함
iso_format_with_timezone = now.strftime('%Y-%m-%dT%H:%M:%S%z')
print(f"ISO 8601 표준 포맷 (시간대 포함): {iso_format_with_timezone}")
strftime 메서드는 datetime 객체를 특정 형식의 문자열로 변환하는 강력한 도구입니다. 이 메서드를 사용하면 날짜와 시간을 다양한 형식으로 포맷팅할 수 있어, 보고서 작성, 데이터 시각화, 로그 기록 등에서 유용하게 활용할 수 있습니다.
LightGBM(Light Gradient Boosting Machine)은 Microsoft에서 개발한 고성능 그래디언트 부스팅 프레임워크입니다.
기존의 그래디언트 부스팅(Gradient Boosting)방법론을 개선하여 대규모 데이터셋에서도 빠른 학습과 예측을 제공하도록 설계되었습니다.
LightGBM은 특히 대규모 데이터와 복잡한 특징 공간을 가진 문제에서 빠른 처리 속도와 적은 메모리 사용을 강점으로 가집니다.
1 - 1. LightGBM의 역사
GBDT(Gradient Boosting Decision Tree)는 널리 사용되는 기계학습 알고리즘인데, 여러 효과적인 구현 중 하나가 XGBoost 모델입니다.
이 알고리즘은 특성 차원이 높을 때와 모든 가능한 분할 지점의 정보 이득을 추정해야 할 때 시간이 많이 소요되는 문제가 있습니다.
이를 극복하기 위해 LightGBM이 개발되었는데, Gradient-based One-side Sampling(GOSS)과 Exclusive Feature Bundling(EFB)과 같은 알고리즘을 사용했습니다.
이 알고리즘을 통해 전체 데이터셋의 일부만을 사용하여 각 트리를 훈련시킬 수 있으며, 고차원의 희소 특징을 효율적으로 처리할 수 있습니다.
2. LightGBM 특징 및 인기요인
LightGBM은 데이터의 개수가 적을 때(10000개 이하) 과적합이 발생할 수 있지만 다양한 장점 덕분에 자주 사용됩니다.
고속처리 및 효율성
LightGBM은 병렬 처리 및 데이터 샘플링 최적화를 통해 기존 그래디언트 부스팅 방식보다 훨씬 빠른 학습이 가능하게 합니다.
메모리 효율성을 통한 최적화
연속형 변수에 대해 구간을 만듦으로써 계산 과정에서 메모리 사용량을 줄입니다.
기존 방식에 비해 높은 처리 속도를 제공하며, 리소스가 제한적인 환경에서도 효율적으로 모델이 운용될 수 있도록 합니다.
결측치 자동 처리
별도의 결측치 처리 과정 없이도, 알고리즘은 결측치가 있는 데이터를 자동으로 인식하고 이를 학습 과정에 사용합니다.
범주형 변수 자동 처리
LightGBM은 범주형 변수를 효과적으로 처리할 수 있습니다.
자료형을 category로 바꾸어 주면 되며, 이외의 별도의 인코딩 과정이 필요하지 않습니다.
target = train['credit']
independent = train.drop(['index', 'credit'], axis = 1)
object_cols = [col for col in independent.columns if independent[col].dtype == "object"]
independent[object_cols] = independent[object_cols].astype('category')
위와 같은 형식으로 바꿔주는 작업을 거치면 됩니다.
스케일링 불필요
LightGBM은 트리 기반의 모델로서 입력 변수의 스케일에 민감하지 않습니다.
따라서 별도의 스케일링 작업 없이도 충분히 학습할 수 있습니다.
높은 정확도
LightGBM은 XGBoost와 비교하여 동등하거나 때때로 더 뛰어난 정확도를 제공합니다.
3. XGBoost 모델과의 차이
3.1 XGBoost란?
XGBoost(eXtreme Gradient Boosting)는 고성능 그래디언트 부스팅 라이브러리로, 정형 데이터 분석 대회에서 널리 사용되어 왔습니다.
XGBoost는 그래디언트 부스팅의 전통적인 방식을 발전시켜 특히 병렬 처리와 과적합 방지 기능에서 강력한 성능을 발휘합니다.
3.2 LightGBM vs XGBoost
XGBoost와 LightGBM은 모두 그래디언트 부스팅에 기반한 라이브러리이지만, 주요 차이점이 몇 가지 있습니다.
이들은 모두 데규모 데이터셋에서 뛰어난 성능을 제공하며, 병렬 처리 기능을 통해 훈련 속도를 향상시킵니다.
차이점1. 성장 방식
XGBoost는 Level-wise 방식을 사용하여 균형 잡힌 트리를 만들어 과적합을 방지하는 반면,
LightGBM은 Leaf-wise 방식을 사용하여 비대칭적인 트리를 빠르게 성장시킬 수 있습니다.
[Level-wise]
위의 이미지는 Level-wise 성장 방식을 나타낸 것입니다.
Level-wise 성장 방식에서는 모든 노드가 같은 레벨에 있을 때까지 자식 노드를 확장합니다.
Level-wise 성장 방식의 경우 트리가 균형 성장을 하면서 트리의 높이가 최소화되기 때문에 과적합 방지할 수 있다는 장점이 있지만, 많은 메모리를 사용한다는 단점이 있습니다.
[Leaf-wise]
반면, Leaf-wise 접근 방식은 트리의 성장을 최적화하여 가장 큰 손실 감소를 제공하는 노드를 우선적으로 확장합니다.
이 방법은 종종 더 깊은 트리를 만들어 과적합의 우려가 있지만, 적절하게 모델을 구성할 경우 과적합의 위험을 관리하면서도 정확한 모델을 빠르게 구축할 수 있습니다.
차이점2. 속도 및 대규모 데이터 처리
XGBoost는 병렬 처리 기능을 사용하여 동시에 트리를 구축하고 학습 속도를 향상시키는 능력이 있습니다.
그러나 이 과정에서 전체 데이터셋의 모든 특성을 스캔해야 하므로, 매우 큰 데이터셋의 경우 여전히 상당한 계산 비용과 시간이 소요될 수 있습니다.
LightGBM은 히스토그램 기반 분할 방식을 사용하여 이러한 계산 비용을 대폭 줄입니다.
이 방식에서 LightGBM은 데이터의 모든 연속형 변수를 미리 정의된 구간(bin)으로 변환하고, 이 구간 정보를 바탕으로 트리의 분할을 결정합니다.
이 방법은 데이터를 스캔하는 데 필요한 시간을 크게 줄이며, 메모리 사용도 최소화합니다.
차이점3. 범주형 변수 처리
XGBoost는 범주형 데이터를 처리하기 위해 라벨 인코딩, 원 핫 인코딩과 같이 수치형 데이터로 변환을 해야합니다.
반면, LightGBM은 범주형 변수의 자료형을 카테고리로 변환하기만 해도 학습이 가능합니다.
4. LightGBM 활용
LightGBM은 지도학습 라이브러리로, 주로 정형 데이터를 분석할 때 사용합니다.
5. LightGBM 세부설정
5.1. 주요 하이퍼파라미터
n_esitmators: 부스팅 단계의 횟수, 즉 모델이 생성할 트리의 수를 지정합니다. 해당 하이퍼파라미터의 값이 클수록 더 많은 트리를 모델에 추가하여 복잡한 데이터 패턴을 학습할 수 있으나, 높은 값은 과적합을 초래할 수 있습니다.
max_depth: 트리의 최대 깊이를 설정합니다. 깊이가 깊어질수록 모델은 더 복잡해지며, 과적합의 위험이 커집니다.
num_leaves: 트리가 가질 수 있는 리프 노드(말단 노드)의 수를 지정합니다. 리프 노드는 루트 노드(최상위 노드)와 내부 노드(분기 노드)를 제외한, 최종적인 결정이 이루어지는 노드를 의미합니다. 이 값이 크면 모델의 복잡도가 증가하여 예측 성능이 향상될 수 있지만, 너무 크면 과적합을 유발할 수 있습니다.
6. LightGBM 모델 학습 - 분류
6-1. 독립변수, 종속변수 설정 및 범주형 자료형 변환
종속변수(target)를 분리하고, 나머지 변수들을 독립변수(independent)로 사용합니다.
범주형 변수들은 LightGBM이 데이터를 처리할 수 있도록 category로 데이터 타입을 변환합니다. 이 변환은 문자열 변수를 인코딩 등의 방법을 이용하여 전처리하지 않는 한 LightGBM 모델을 사용하기 위해서는 필수적인 과정입니다.
target = train['credit']
independent = train.drop(['index', 'credit'], axis = 1)
object_cols = [col for col in independent.columns if independent[col].dtype == "object"]
independent[object_cols] = independent[object_cols].astype('category')
6-2. 학습/검증 데이터 설정
독립변수 independent와 종속변수 target을 학습과 검증 데이터로 분리합니다.
이후에는 학습 데이터로 LightGBM 모델을 학습시키고, 검증 데이터를 이용하여 각 시도에 대한 검증 점수를 확인하면 됩니다.
결측치 처리를 하지 않고 문자열 변수의 자료형을 category로만 설정하고, 인코딩과 같은 방법을 사용하지 않음에도 학습이 진행되는데 그 이유는 이 모델이 결측치와 범주형 변수를 자동으로 처리할 수 있는 기능이 있어, 모델 학습에서 별도의 전처리 없이도 학습이 가능합니다.
from lightgbm import LGBMClassifier
# LightGBM 모델 정의 및 학습
base_lgbm = LGBMClassifier(random_state = 42)
base_lgbm.fit(X_train, y_train)
# 검증점수 확인print("LGBM 모델 정확도:", base_lgbm.score(X_valid, y_valid))
6-4. 하이퍼파라미터 설정
from lightgbm.callback import early_stopping, log_evaluation
# LightGBM 모델 정의
tuning_lgbm = LGBMClassifier(n_estimators=300, max_depth=6, random_state = 42)
# 조기 종료와 학습 로그 출력 콜백 정의
early_stop = early_stopping(stopping_rounds=5)
# 조기 종료를 설정하는 부분이며,이 코드의 경우 5번의 부스팅 동안 성능 개선이 없을 때 종료합니다.
log_eval = log_evaluation(period=20)
## 모델 학습 과정에서 지정된 주기(20라운드)마다 평가지표를 출력합니다.# 모델 학습
tuning_lgbm.fit(
X_train, y_train,
eval_set=[(X_valid, y_valid)],
eval_metric='multi_logloss',
callbacks=[early_stop, log_eval]
)
# 정확도 출력print("하이퍼파라미터가 튜닝된 LGBM 모델 정확도:", tuning_lgbm.score(X_valid, y_valid))
6-5. 학습 과정의 성능 지표 모니터링
평가지표의 변화가 멈추거나, 특정 지점에서 성능이 개선되지 않는다면 과적합이 발생하거나 학습이 더 이상 효과적이지 않음을 의미할 수 있습니다. 이러한 경우 모델 학습 중 모니터링을 하면서 적절한 트리의 수가 얼마인지(n_estimators), 조기종료(early_stopping)를 해야할지 여부를 결정할 수 있습니다.
로그 손실(log loss)은 분류모델의 평가지표이며, 모델이 잘 예측을 수행할수록 낮은 값을 가집니다.
import lightgbm as lgb
import matplotlib.pyplot as plt
# 모델 학습 중 사용된 metric과 동일한 'multi_logloss'를 사용
loss_plot = lgb.plot_metric(tuning_lgbm.evals_result_, metric='multi_logloss')
## plot_metric 함수는 LightGBM의 학습 중에 기록된 평가지표를 시각화할 때 사용합니다. ## 각 반복마다 기록된 평가 지표는 evals_result_ 속성에 기록되는데,## 이 속성에는 지정된 검증 데이터셋에 대한 모델의 성능 평가 결과가 저장됩니다.## 이 코드를 실행함으로써 평가지표가 어떻게 변화하는지 확인할 수 있습니다.
plt.show()
plot_importance 함수는 모델 학습 중 각 피처의 중요도를 바 차트(bar chart)로 시각화하는 데 사용됩니다.
이 함수는 tuning_lgbm.booster_ 에서 제공하는 정보를 기반으로 작동합니다.
booster_ 속성은 LightGBM 모델의 부스터(Booster) 객체를 포함하고 있으며, 이는 모델이 생성한 결정 트리들의 집합입니다.
각 피처의 중요도는 이 결정 트리들 내에서 해당 피처가 얼마나 자주 사용되었는지를 통해 계산됩니다.
max_num_features 매개변수를 통해 표시되는 최대 피처의 수를 제한하여, 가장 중요도가 높은 피처만 시각화하도록 설정할 수 있습니다.
6-7. LightGBM 예측값
pred = tuning_lgbm.predict(X_valid)
logloss_pred = tuning_lgbm.predict(X_valid)
print(pred)
print('-'*40)
print(logloss_pred)
7. XGBoost와 학습 속도 비교
import pandas as pd
import time
from sklearn.model_selection import train_test_split
from lightgbm import LGBMClassifier
from xgboost import XGBClassifier
train = pd.read_csv('당뇨_train.csv')
target_col = 'Outcome'
target = train[target_col]
train = train.drop(['ID', target_col], axis = 1)
# 2. 학습 / 검증 데이터 분리
X_train, X_valid, y_train, y_valid = train_test_split(train, target, test_size=0.2, random_state=42)
# LightGBM 모델 학습
start_lgbm = time.time()
model_lgbm_classifier = LGBMClassifier(random_state = 42)
model_lgbm_classifier.fit(X_train, y_train)
end_lgbm = time.time()
# XGBoost 모델 학습
start_xgb = time.time()
model_xgb_classifier = XGBClassifier(random_state = 42)
model_xgb_classifier.fit(X_train, y_train)
end_xgb = time.time()
valid_score_lgbm_classifier = model_lgbm_classifier.score(X_valid, y_valid)
valid_score_xgb_classifier = model_xgb_classifier.score(X_valid, y_valid)
print("LGBM Classifier Validation Score:", valid_score_lgbm_classifier)
print("XGB Classifier Validation Score:", valid_score_xgb_classifier)
print("LGBM 모델의 학습 시간은", end_lgbm-start_lgbm,"초 입니다.")
print("XGB 모델의 학습 시간은", end_xgb-start_xgb,"초 입니다.")
8. LightGBM 모델 학습 - 회귀
8-1. 학습
from lightgbm.callback import early_stopping, log_evaluation
from lightgbm import LGBMRegressor
# LightGBM 모델 초기화
tuning_lgbm = LGBMRegressor(
n_estimators=300,
max_depth=8,
learning_rate= 0.01,
random_state = 42
)
# 조기 종료 및 학습 로그 출력 콜백 정의
early_stop = early_stopping(stopping_rounds=15)
log_eval = log_evaluation(period=20)
# 모델 학습
tuning_lgbm.fit(
X_train, y_train,
eval_set=[(X_valid, y_valid)],
eval_metric='rmse',
callbacks=[early_stop, log_eval]
)
# 정확도 출력print("LightGBM 회귀모델의 결정계수:", tuning_lgbm.score(X_valid, y_valid))
8-2. 평가지표 변화 추이 확인
import lightgbm as lgb
import matplotlib.pyplot as plt
# 모델 학습 중 사용된 metric과 동일한 'rmse'를 사용
loss_plot = lgb.plot_metric(tuning_lgbm.evals_result_, metric='rmse')
plt.show()
변수 pattern에 정의된 패턴은 공백(\s)과 하이픈(-), 공백(\s)을 포함한 뒤의 모든 문자(.)를 찾는 것을 목표로 한다.
* 은 0회 이상 반복될 수 있다는 것을 의미한다.
str.replace 메서드는 정규표현식을 사용하여 문자열에서 원하는 패턴을 찾아 다른 문자열로 치환할 수 있게 해주는 함수이다.
코드는 pattern을 발견하면, 그 패턴에 해당하는 문자열을 제거('')한다.
regex = True은 해당 패턴에서 정규 표현식을 사용한다는 의미이다.
시군구 열 데이터 정제 : 캡처 그룹을 활용한 지역명 추출
캡처 그룹이란?
캡처 그룹(capture group)은 정규표현식 내에서 특정 부분을 하나의 단위로 묶기 위해 사용하는 기술이다.
이를 통해 복잡한 문자열 패턴 내에서 특정 부분을 식별하고 추출하는 데 사용된다.
각 캡처 그룹은 괄호 ()를 사용하여 정의되며, 정규표현식 내에서 하나 이상의 문자열을 그룹으로 묶을 수 있는데, 복수의 선택 사항 중 하나를 식별하고, 필요한 부분만을 추출할 수 있다.
사용방법
r'()' 의 괄호 () 안에 여러 문자열 또는 패턴을 넣어 복수의 선택지 중에서 일치하는 요소를 찾을 수 있다.
r'(창원 | 마산)' 캡처그룹은 '창원' 또는 '마산'과 일치하는 문자열을 찾는다.
이러한 방식은 데이터에서 특정 키워드나 패턴을 필터링할 때 유용하다.
또한, 캡처 그룹은 정규표현식 내에서 특정 부분의 반복을 지정하는 데에도 사용된다.
예를 들어 r'(ab)+' 는 'ab', 'abab', 'ababab' ... 등 문자열이 한 번 이상 반복되는 경우와 일치한다.
pattern = r'(남구|달서구)'# '남구' 또는 '달서구'를 추출하고, 해당되지 않는 경우 '기타'로 표시
train['시군구_특정'] = train['시군구'].str.extract(pattern)
train['시군구_특정'] = train['시군구_특정'].fillna('기타')
display(train.head(3))
로지스틱 회귀분석은 20세기 초에 발전한 통계방법입니다. 이 모델은 로지스틱 함수에서 이진 분류 문제를 풀기위해 발전되었습니다. 이 모델은 주로 예/아니오, 성공/실패와 같이 두 가지 범주로 결과가 나뉘는 경우에 사용됩니다. 로지스틱 회귀분석의 핵심 개념은 다음과 같습니다.
확률 추정: 로지스틱 회귀는 주어진 데이터가 특정 클래스에 속할 확률을 추정합니다. 이 확률은 0과 1 사이의 값으로, 예측된 확률이 특정 임계값(보통 0.5) 이상이면 하나의 클래스로, 이하면 다른 클래스로 분류됩니다.
시그모이드 함수: 로지스틱 회귀는 시그모이드 함수(또는 로지스틱 함수)를 사용하여 입력 데이터의 선형 조합을 0과 1 사이의 확률 값으로 변환합니다. 시그모이드 함수는 S자 형태의 곡선을 그리며, 이 함수는 선형 조합의 결과를 확률로 매핑합니다.
최대 우도 추정: 로지스틱 회귀 모델은 최대 우도 추정(Maximum Likelihood Estimation, MLE) 방법을 사용하여 모델 파라미터를 추정합니다. 이는 주어진 데이터에 대해 관측된 결과의 확률을 최대화하는 파라미터 값을 찾는 과정입니다.
이진 분류: 로지스틱 회귀는 기본적으로 이진 분류를 위해 설계되었지만, 원-대-다(One-vs-Rest) 방식이나 원-대-원(One-vs-One) 방식을 통해 다중 클래스 분류 문제에도 적용될 수 있습니다.
1.2. 언제 사용하면 좋을까요?
로지스틱 회귀분석은 주로 이진 분류(Binary Classification) 문제를 해결하기 위해 사용됩니다. 이는 결과가 두 가지 범주(예: 예/아니오, 성공/실패) 중 하나로 나누어지는 경우에 적합합니다. 주로 데이터 수가 많지 않은 경우 간단한 모델이 필요할 때 사용합니다. 또한, 분석결과에 대한 설명과 해석이 중요할 때 사용하면 좋습니다.
1.3. 장점
해석 용이성: 로지스틱 회귀 모델은 결과를 해석하기 쉽습니다. 각 특성의 가중치를 분석하여 어떤 특성이 결과에 더 큰 영향을 미치는지 이해할 수 있습니다.
확률 추정: 결과의 확률을 제공하여, 단순한 분류뿐만 아니라 결과의 불확실성을 평가할 수 있습니다.
유연성: 다른 회귀 모델과 마찬가지로 다양한 유형의 데이터에 적용할 수 있으며, 커널 방법 등을 사용해 비선형 관계를 모델링할 수도 있습니다.
1.4. 한계점
비선형 관계의 제한적 모델링: 로지스틱 회귀는 기본적으로 선형 관계를 가정합니다. 복잡한 비선형 관계를 모델링하기 위해서는 추가적인 기법이 필요합니다.
특성 선택의 중요성: 중요하지 않거나 상관관계가 높은 특성이 포함되어 있으면 모델의 성능이 저하될 수 있습니다.
과적합의 위험성: 특성의 수가 많거나 모델이 복잡할 경우 과적합(Overfitting)이 발생할 수 있으며, 이를 피하기 위해 적절한 규제가 필요합니다.
2. 로지스틱 회귀분석 이론
오즈(Odds): 특정 사건이 발생할 확률과 그 사건이 발생하지 않을 확률 간의 비율 입니다.
예를 들어, 어떤 사건의 발생 확률이 0.75라고 가정해 봅시다. 이 경우, 이 사건이 발생하지 않을 확률은 0.25가 됩니다. 그러면 이 사건의 오즈는 다음과 같이 계산됩니다. 이것은 사건이 발생할 확률이 발생하지 않을 확률보다 3배 높다는 것을 의미합니다.
로그 변환: 로지스틱 회귀에서는 종속 변수의 로그 오즈(log odds)를 독립 변수들의 선형 조합으로 모델링합니다. 즉, 로지스틱 회귀는 확률을 직접 모델링하지 않고, 오즈를 로그 변환하여 사용합니다. 오즈는 0이상의 값만 존재하지만, 로그변환을 하면 값의 범위가 실수 전체로 확장되어, 종속변수와 독립 변수 사이의 관계를 선형방정식으로 표현할 수 있습니다. 로그 오즈는 다음과 같이 정의됩니다.
이 식에서 각각의 요소는 다음과 같은 의미를 갖습니다
β0,β1,β2,β3...,βn은 모델의계수(가중치)입니다. 이들은 각 독립 변수가 종속 변수에 미치는 영향의 크기를 나타냅니다.
X1,X2,... ,Xn은독립 변수(설명 변수)입니다. 이들은 분석 대상이 되는 데이터의 특성을 나타냅니다.
위 식을P(Y=1)P(Y=1)에 대해 정리하면 아래와 같습니다.
위 식은 시그모이드 함수와 같은 형태입니다. 데이터의 독립 변수들을 이용하여 하나의 선형 값z를 계산합니다. 그리고 0과 1 사이의 값(확률)으로 변환합니다.
로지스틱 회귀에서 시그모이드 함수는 입력 데이터의 선형 조합을 확률 값으로 변환하는 데 사용됩니다. 예를 들어, 로지스틱 회귀 모델에서는 데이터의 특성과 가중치의 선형 조합을 계산한 다음, 이 값을 시그모이드 함수의 입력으로 사용하여 0과 1 사이의 값을 얻습니다. 이 값은 특정 클래스에 속할 확률로 해석됩니다. 식으로 표현하면 아래와 같습니다.
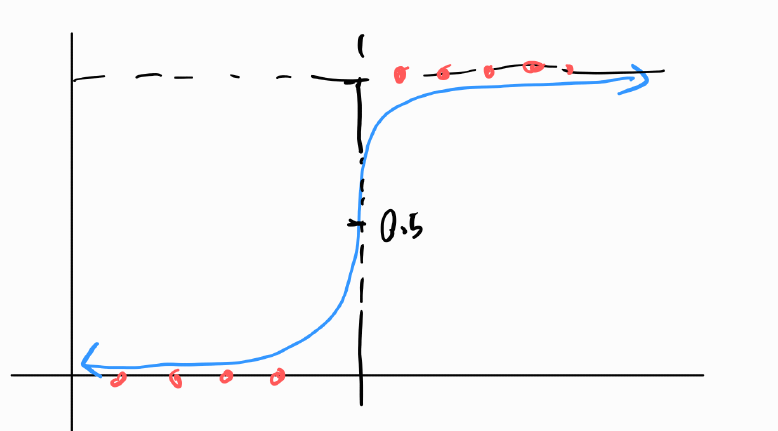
위 수식을 그래프로 표현하면 아래와 같습니다.
빨간 점: 실제 데이터
파란색 선: 로지스틱 회귀모델
3. LogisticRegression() 매개변수
penalty
정규화 종류. 'l1', 'l2', 'elasticnet', 'none' 중 선택. 기본값은 'l2'.
dual
이중 또는 원시 방법 선택. 기본값은False.
tol
최적화 중단을 위한 허용 오차. 기본값은 1e-4.
C
정규화 강도의 역수. 값이 작을수록 강한 정규화. 기본값은 1.0.
fit_intercept
모델에 절편(상수 항) 포함 여부. 기본값은True.
intercept_scaling
절편에 적용되는 스케일링 팩터.fit_intercept가True일 때 사용.
class_weight
클래스 불균형을 처리하기 위한 가중치. 기본값은None.
random_state
난수 발생기 시드. 결과 재현성을 위함.
solver
최적화 문제를 해결하기 위한 알고리즘. 'newton-cg', 'lbfgs', 'liblinear', 'sag', 'saga' 등 선택 가능.
max_iter
최적화를 위한 최대 반복 횟수. 기본값은 100.
multi_class
다중 클래스 분류 전략. 'auto', 'ovr', 'multinomial' 중 선택.
verbose
로그 출력 상세도.
warm_start
이전 호출의 솔루션을 재사용하여 피팅을 초기화 여부. 기본값은False.
n_jobs
병렬 처리를 위한 CPU 코어 수. 기본값은None(1개 코어 사용).
예시
model = LogisticRegression(penalty='l2', # L2 정규화 사용
C=0.5, # 정규화 강도 (낮을수록 강한 정규화)
fit_intercept=True, # 절편을 포함
random_state=42, # 결과 재현을 위한 난수 시드
solver='lbfgs', # 최적화를 위한 알고리즘
max_iter=100, # 최대 반복 횟수
multi_class='auto', # 다중 클래스 처리 방식
verbose=0, # 로그 출력 정도 (0은 출력하지 않음)
n_jobs=1# 사용할 CPU 코어 수 (1은 하나의 코어 사용)
)
4. 파이썬 예제코드
# 데이터 셋 준비
X, y = make_classification(n_features=1, n_samples=300,n_redundant=0, n_informative=1,
n_clusters_per_class=1, class_sep=0.5,random_state=7)
X.shape, y.shape
make_classifications 함수는 Scikit-learn의 데이터셋 생성 도구로 연습용 데이터셋을 생성한다.
파라미터 설명
n_features = 1: 독립 변수(특성)의 수를 1로 설정
n_samples = 300: 샘플(데이터 포인트)의 총 개수를 300으로 설정
n_redundant = 0: 중복되는(불필요한) 특성의 수를 0으로 설정
n_informative = 1: 유익한(목표 변수와 관계 있는) 특성의 수를 1로 설정
n_clusters_per_class = 1: 각 클래스별 클러스터의 수를 1로 설정. 이는 각 클래스가 하나의 밀집된 클러스터로 구성되어 있음을 의미한다.
class_sep = 0.5: 클래스 간 분리 정도를 설정한다. 값이 클수록 클래스 간의 분리가 뚜렷해진다.
random_state = 0: 결과의 재현 가능성을 위해 랜덤 상태(seed)를 0으로 고정한다.
로지스틱 회귀분석 결과 해석
import statsmodels.api as sm
X_con = sm.add_constant(X) # 상수항 추가
sm_model = sm.Logit(y, X_con) # 모델 생성
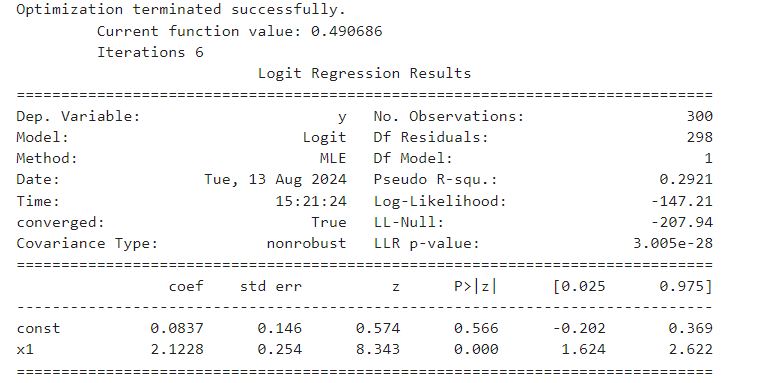
result = sm_model.fit() # 모델 학습print(result.summary()) # 결과 확인
Dep.Variable: 종속 변수 Y
No.Observations: 분석에 사용된 관측치의 수
Df Residuals: 잔차의 자유도는 97
Method: 모델 최적화 방법으로 사용된 방법은 MLE(Maximum Likelihood Estimation)
Pseudo R-squ: 이 모델이 데이터에 대해 어느 정도 설명력을 가지고 있는지 나타낸다. 높을수록 모델이 데이터에 대해 더 높은 설명력을 가진다고 할 수 있음.
Log-Likelihood: 로그 우도 값은 -50.00
LL-Null: 모델 없이(상수항만 있는 경우)로그 우도 값은 -100.00
LLR p-value: 로그 우도 비 테스트의 p-값은 1.000e-10로, 모델이 통계적으로 유의미함을 의미.
우도(Likelihood)
: 우도는 주어진 모델 매개변수에서 관측된 데이터가 나타낼 확률을 의미한다. 로지스틱 회귀에서는 관측된 데이터가 주어진 매개변수(예: 회귀 계수)에 대해 나타날 가능성을 수치적으로 나타낸다.
베타값에서 관측치 y가 나타날 조건부 확률이다.
로그 우도(Log-Likelihood)
우도의 로그 값을 취하는 이유는 여러가지이다.
첫째, 로그를 취하면 수치적 안정성이 증가한다. 우도는 확률의 곱셈으로 계산되기 때문에 매우 작은 숫자가 될 수 있으며, 이는 컴퓨터에서의 계산에서 부정확성을 야기할 수 있다. 로그를 취하면 곱셈이 합셈으로 변환되어 이러한 문제를 완화한다.
둘째, 로그를 취하면 최적화 문제를 해결하기가 수학적으로 더 쉬워진다. 즉, 최대 우도를 찾는 문제가 더 단순한 형태로 변환된다.
Log-Likelihood 값은 높을수록 좋다. 높은 값은 모델이 데이터를 더 잘 설명하고 있음을 의미한다.