1. 로지스틱 회귀분석 개념
1.1. 로지스틱 회귀분석이란?
로지스틱 회귀분석은 20세기 초에 발전한 통계방법입니다. 이 모델은 로지스틱 함수에서 이진 분류 문제를 풀기위해 발전되었습니다. 이 모델은 주로 예/아니오, 성공/실패와 같이 두 가지 범주로 결과가 나뉘는 경우에 사용됩니다. 로지스틱 회귀분석의 핵심 개념은 다음과 같습니다.
- 확률 추정: 로지스틱 회귀는 주어진 데이터가 특정 클래스에 속할 확률을 추정합니다. 이 확률은 0과 1 사이의 값으로, 예측된 확률이 특정 임계값(보통 0.5) 이상이면 하나의 클래스로, 이하면 다른 클래스로 분류됩니다.
- 시그모이드 함수: 로지스틱 회귀는 시그모이드 함수(또는 로지스틱 함수)를 사용하여 입력 데이터의 선형 조합을 0과 1 사이의 확률 값으로 변환합니다. 시그모이드 함수는 S자 형태의 곡선을 그리며, 이 함수는 선형 조합의 결과를 확률로 매핑합니다.
- 최대 우도 추정: 로지스틱 회귀 모델은 최대 우도 추정(Maximum Likelihood Estimation, MLE) 방법을 사용하여 모델 파라미터를 추정합니다. 이는 주어진 데이터에 대해 관측된 결과의 확률을 최대화하는 파라미터 값을 찾는 과정입니다.
- 이진 분류: 로지스틱 회귀는 기본적으로 이진 분류를 위해 설계되었지만, 원-대-다(One-vs-Rest) 방식이나 원-대-원(One-vs-One) 방식을 통해 다중 클래스 분류 문제에도 적용될 수 있습니다.
1.2. 언제 사용하면 좋을까요?
로지스틱 회귀분석은 주로 이진 분류(Binary Classification) 문제를 해결하기 위해 사용됩니다. 이는 결과가 두 가지 범주(예: 예/아니오, 성공/실패) 중 하나로 나누어지는 경우에 적합합니다. 주로 데이터 수가 많지 않은 경우 간단한 모델이 필요할 때 사용합니다. 또한, 분석결과에 대한 설명과 해석이 중요할 때 사용하면 좋습니다.
1.3. 장점
- 해석 용이성: 로지스틱 회귀 모델은 결과를 해석하기 쉽습니다. 각 특성의 가중치를 분석하여 어떤 특성이 결과에 더 큰 영향을 미치는지 이해할 수 있습니다.
- 확률 추정: 결과의 확률을 제공하여, 단순한 분류뿐만 아니라 결과의 불확실성을 평가할 수 있습니다.
- 유연성: 다른 회귀 모델과 마찬가지로 다양한 유형의 데이터에 적용할 수 있으며, 커널 방법 등을 사용해 비선형 관계를 모델링할 수도 있습니다.
1.4. 한계점
- 비선형 관계의 제한적 모델링: 로지스틱 회귀는 기본적으로 선형 관계를 가정합니다. 복잡한 비선형 관계를 모델링하기 위해서는 추가적인 기법이 필요합니다.
- 특성 선택의 중요성: 중요하지 않거나 상관관계가 높은 특성이 포함되어 있으면 모델의 성능이 저하될 수 있습니다.
- 과적합의 위험성: 특성의 수가 많거나 모델이 복잡할 경우 과적합(Overfitting)이 발생할 수 있으며, 이를 피하기 위해 적절한 규제가 필요합니다.
2. 로지스틱 회귀분석 이론
오즈(Odds): 특정 사건이 발생할 확률과 그 사건이 발생하지 않을 확률 간의 비율 입니다.
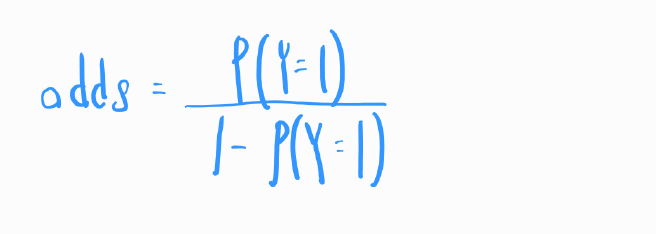
예를 들어, 어떤 사건의 발생 확률이 0.75라고 가정해 봅시다. 이 경우, 이 사건이 발생하지 않을 확률은 0.25가 됩니다. 그러면 이 사건의 오즈는 다음과 같이 계산됩니다. 이것은 사건이 발생할 확률이 발생하지 않을 확률보다 3배 높다는 것을 의미합니다.
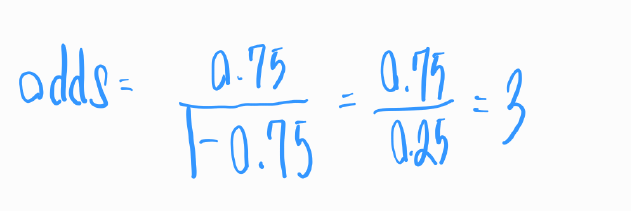
로그 변환: 로지스틱 회귀에서는 종속 변수의 로그 오즈(log odds)를 독립 변수들의 선형 조합으로 모델링합니다. 즉, 로지스틱 회귀는 확률을 직접 모델링하지 않고, 오즈를 로그 변환하여 사용합니다. 오즈는 0이상의 값만 존재하지만, 로그변환을 하면 값의 범위가 실수 전체로 확장되어, 종속변수와 독립 변수 사이의 관계를 선형방정식으로 표현할 수 있습니다. 로그 오즈는 다음과 같이 정의됩니다.
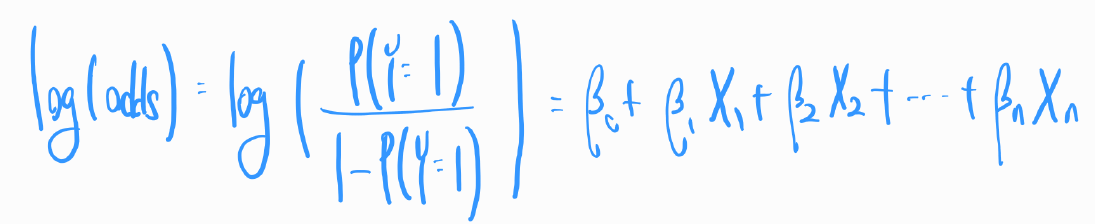
이 식에서 각각의 요소는 다음과 같은 의미를 갖습니다
- , , , ..., 은 모델의 계수(가중치) 입니다. 이들은 각 독립 변수가 종속 변수에 미치는 영향의 크기를 나타냅니다.
- , ,... ,Xn 은 독립 변수(설명 변수) 입니다. 이들은 분석 대상이 되는 데이터의 특성을 나타냅니다.
위 식을 P(Y=1)에 대해 정리하면 아래와 같습니다.
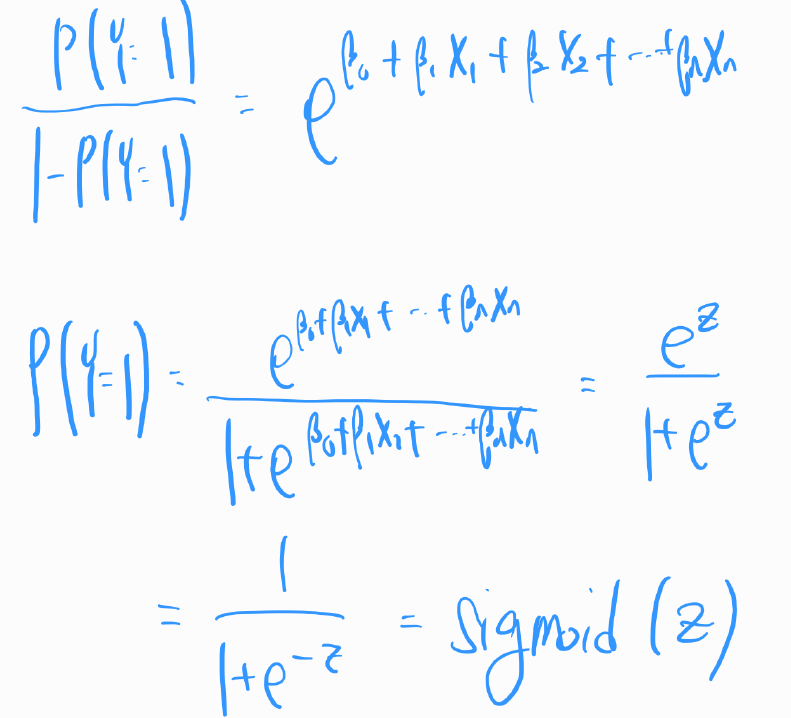
위 식은 시그모이드 함수와 같은 형태입니다. 데이터의 독립 변수들을 이용하여 하나의 선형 값 z를 계산합니다. 그리고 0과 1 사이의 값(확률)으로 변환합니다.
로지스틱 회귀에서 시그모이드 함수는 입력 데이터의 선형 조합을 확률 값으로 변환하는 데 사용됩니다. 예를 들어, 로지스틱 회귀 모델에서는 데이터의 특성과 가중치의 선형 조합을 계산한 다음, 이 값을 시그모이드 함수의 입력으로 사용하여 0과 1 사이의 값을 얻습니다. 이 값은 특정 클래스에 속할 확률로 해석됩니다. 식으로 표현하면 아래와 같습니다.

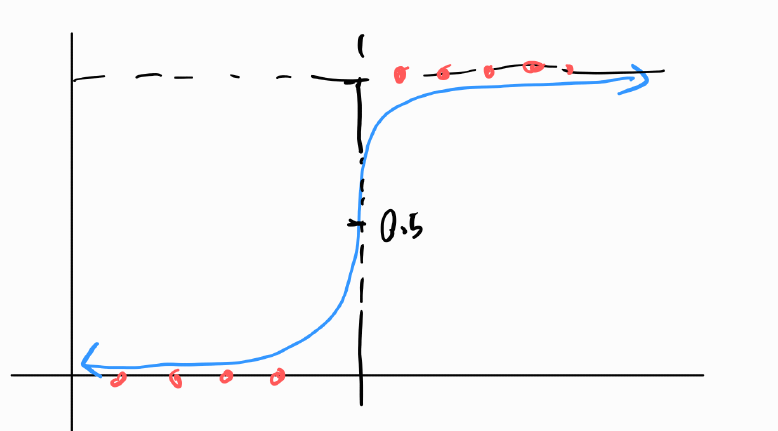
위 수식을 그래프로 표현하면 아래와 같습니다.
- 빨간 점: 실제 데이터
- 파란색 선: 로지스틱 회귀모델
3. LogisticRegression() 매개변수
| penalty | 정규화 종류. 'l1', 'l2', 'elasticnet', 'none' 중 선택. 기본값은 'l2'. |
| dual | 이중 또는 원시 방법 선택. 기본값은 False. |
| tol | 최적화 중단을 위한 허용 오차. 기본값은 1e-4. |
| C | 정규화 강도의 역수. 값이 작을수록 강한 정규화. 기본값은 1.0. |
| fit_intercept | 모델에 절편(상수 항) 포함 여부. 기본값은 True. |
| intercept_scaling | 절편에 적용되는 스케일링 팩터. fit_intercept가 True일 때 사용. |
| class_weight | 클래스 불균형을 처리하기 위한 가중치. 기본값은 None. |
| random_state | 난수 발생기 시드. 결과 재현성을 위함. |
| solver | 최적화 문제를 해결하기 위한 알고리즘. 'newton-cg', 'lbfgs', 'liblinear', 'sag', 'saga' 등 선택 가능. |
| max_iter | 최적화를 위한 최대 반복 횟수. 기본값은 100. |
| multi_class | 다중 클래스 분류 전략. 'auto', 'ovr', 'multinomial' 중 선택. |
| verbose | 로그 출력 상세도. |
| warm_start | 이전 호출의 솔루션을 재사용하여 피팅을 초기화 여부. 기본값은 False. |
| n_jobs | 병렬 처리를 위한 CPU 코어 수. 기본값은 None (1개 코어 사용). |
예시
model = LogisticRegression(penalty='l2', # L2 정규화 사용
C=0.5, # 정규화 강도 (낮을수록 강한 정규화)
fit_intercept=True, # 절편을 포함
random_state=42, # 결과 재현을 위한 난수 시드
solver='lbfgs', # 최적화를 위한 알고리즘
max_iter=100, # 최대 반복 횟수
multi_class='auto', # 다중 클래스 처리 방식
verbose=0, # 로그 출력 정도 (0은 출력하지 않음)
n_jobs=1 # 사용할 CPU 코어 수 (1은 하나의 코어 사용)
)
4. 파이썬 예제코드
# 데이터 셋 준비
X, y = make_classification(n_features=1, n_samples=300,n_redundant=0, n_informative=1,
n_clusters_per_class=1, class_sep=0.5,random_state=7)
X.shape, y.shape
make_classifications 함수는 Scikit-learn의 데이터셋 생성 도구로 연습용 데이터셋을 생성한다.
파라미터 설명
- n_features = 1: 독립 변수(특성)의 수를 1로 설정
- n_samples = 300: 샘플(데이터 포인트)의 총 개수를 300으로 설정
- n_redundant = 0: 중복되는(불필요한) 특성의 수를 0으로 설정
- n_informative = 1: 유익한(목표 변수와 관계 있는) 특성의 수를 1로 설정
- n_clusters_per_class = 1: 각 클래스별 클러스터의 수를 1로 설정. 이는 각 클래스가 하나의 밀집된 클러스터로 구성되어 있음을 의미한다.
- class_sep = 0.5: 클래스 간 분리 정도를 설정한다. 값이 클수록 클래스 간의 분리가 뚜렷해진다.
- random_state = 0: 결과의 재현 가능성을 위해 랜덤 상태(seed)를 0으로 고정한다.
로지스틱 회귀분석 결과 해석
import statsmodels.api as sm
X_con = sm.add_constant(X) # 상수항 추가
sm_model = sm.Logit(y, X_con) # 모델 생성
result = sm_model.fit() # 모델 학습
print(result.summary()) # 결과 확인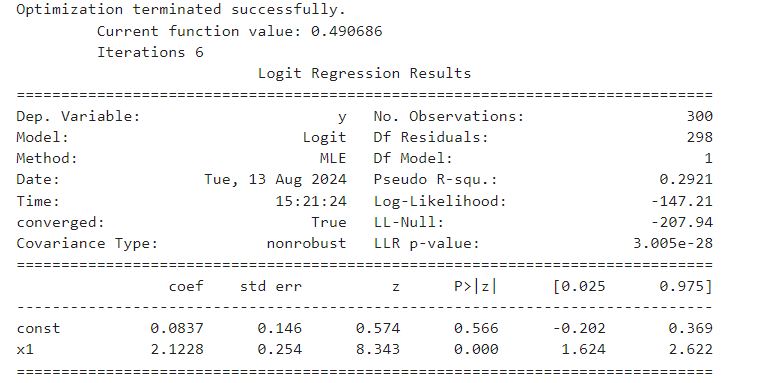
Dep.Variable: 종속 변수 Y
No.Observations: 분석에 사용된 관측치의 수
Df Residuals: 잔차의 자유도는 97
Method: 모델 최적화 방법으로 사용된 방법은 MLE(Maximum Likelihood Estimation)
Pseudo R-squ: 이 모델이 데이터에 대해 어느 정도 설명력을 가지고 있는지 나타낸다. 높을수록 모델이 데이터에 대해 더 높은 설명력을 가진다고 할 수 있음.
Log-Likelihood: 로그 우도 값은 -50.00
LL-Null: 모델 없이(상수항만 있는 경우)로그 우도 값은 -100.00
LLR p-value: 로그 우도 비 테스트의 p-값은 1.000e-10로, 모델이 통계적으로 유의미함을 의미.
우도(Likelihood)
: 우도는 주어진 모델 매개변수에서 관측된 데이터가 나타낼 확률을 의미한다. 로지스틱 회귀에서는 관측된 데이터가 주어진 매개변수(예: 회귀 계수)에 대해 나타날 가능성을 수치적으로 나타낸다.
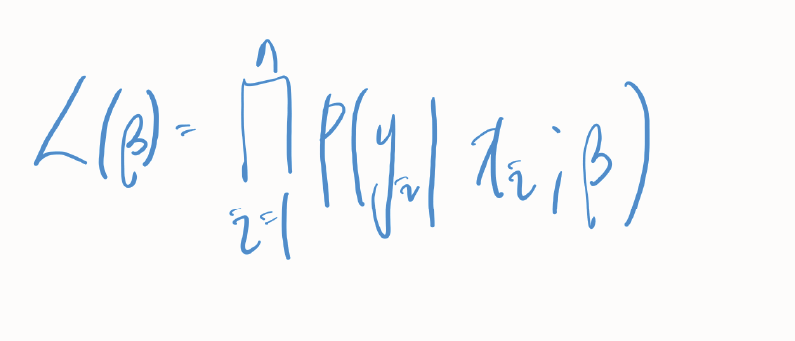
베타값에서 관측치 y가 나타날 조건부 확률이다.
로그 우도(Log-Likelihood)
우도의 로그 값을 취하는 이유는 여러가지이다.
첫째, 로그를 취하면 수치적 안정성이 증가한다. 우도는 확률의 곱셈으로 계산되기 때문에 매우 작은 숫자가 될 수 있으며, 이는 컴퓨터에서의 계산에서 부정확성을 야기할 수 있다. 로그를 취하면 곱셈이 합셈으로 변환되어 이러한 문제를 완화한다.
둘째, 로그를 취하면 최적화 문제를 해결하기가 수학적으로 더 쉬워진다. 즉, 최대 우도를 찾는 문제가 더 단순한 형태로 변환된다.
Log-Likelihood 값은 높을수록 좋다. 높은 값은 모델이 데이터를 더 잘 설명하고 있음을 의미한다.
'프로그래밍 > 머신러닝' 카테고리의 다른 글
| LightGBM (1) | 2024.09.04 |
|---|---|
| 다변량 이상치 탐지 방법 (0) | 2024.08.25 |
| 정규 표현식 (Regular Expression) (0) | 2024.08.23 |
| 혼자 공부하는 머신러닝 + 딥러닝(딥러닝) (0) | 2024.08.08 |
| 혼자 공부하는 머신러닝 + 딥러닝(머신러닝) (0) | 2024.07.19 |