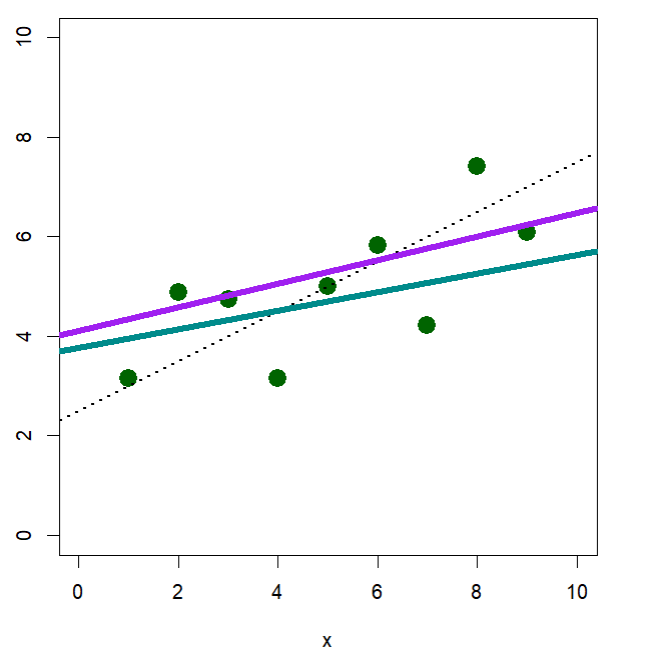
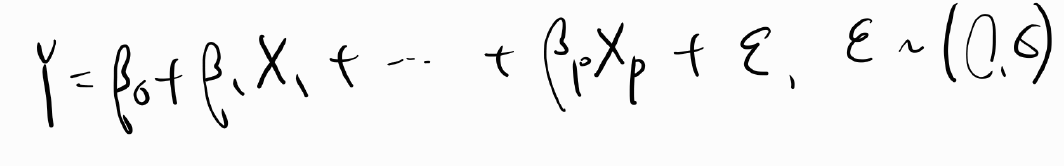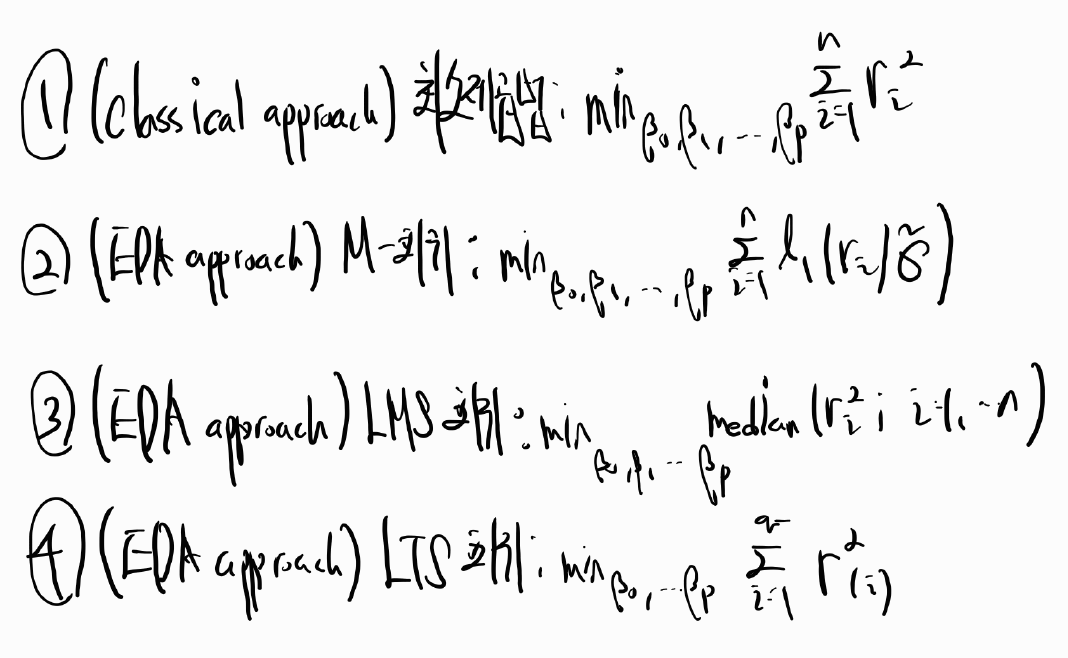# 파일 불러오기 ====
Exam = read.table("/Users/user/OneDrive - 경북대학교/학과/2-1/탐색적자료분석 및 실험/실습파일/exam1.txt", head = T)
head(Exam$score)
# 줄기와 잎그림 확인 ====
stem(Exam$score)
# 줄기 수 줄이기와 늘이기 ====
# 이유는 여러가지 가능성을 열어두고 탐색하기 위함.
## 줄기 수 줄이기 ====
stem(Exam$score, scale = 0.5)
# (0,1), (2,3).... 한 줄에 다 들어감.
# 이렇게하면 이전에 했던 줄기 그림이 쌍봉분포인데 비해 이것의 줄기 그림은 단봉분포의 형태를 취한다. 이것은 너무 단순하여 이 자료의 주요 특성을 잃은 것으로 볼 수도 있다. 즉 2개의 봉우리를 구분하지 못하고 1개만 본 것이다.
## 줄기 수 늘이기 ====
stem(Exam$score, scale = 2)
# 원자료라면 하나였을 줄기가 각각이 줄기가 2개가 생김.
# 일반적으로 줄기 수를 늘이면 늘일수록 많은 수의 봉우리를 보게 되고 반대로 줄기 수를 줄이면 줄일 수록 적은 수의 봉우리를 보게 된다.
## hist ====
hist(Exam$score, nclass = 10, right = F)
# 대용량 크기 확인에 용이하다.
hist(Exam$score, nclass = 20, right = F)
n = 21
for(i in 1:100){
cat("collatz : NOW =", n, "\n")
if (n %% 2 == 0){
n = n / 2
} else {
n = n*3 + 1
}
if(n == 1){
cat("collatz : END =", n, "\n")
break
}
}
사용자 정의 함수
function(<para1>, <para2>, ....){<expression>}
para1, 2 는 매개변수,
expression은 매개변수를 활용한 함수식
예시1
Ex0 = function(x) {7*x+5}
Ex0(3)
Ex1 = function(x){
y = 7*x + 5
# 별도로 객체를 정의하여 값을 저장하면
# 함수를 실행시키더라도 함수값을 출력해주지 않음.
}
Ex1(4)
y
# 함수 안에서 만들어진 변수는 함수가 종료되면 없어짐.
예시2
Ex2 = function(x){
x^2 + 3*x - 6
}
Ex2(10)
반환하고 싶을 때는 return(<object>)를 사용하여야 함.
Ex1 = function(x){
y = 7*x + 5
return(y)
}
Ex1(4)
return을 쓰면 함수를 호출했을 때
함수 내에서 저장한 변수를 return(y)로 반환해줄 수 있음.
return 예시 1
Ex3 = function(x){
a = x^2 + 3*x - 6
b = 2*x^2 - exp(2)
return(a+b)
}
Ex3(10)
Ex5(3, -3:10) 코드는 순서대로 매개변수의 속성에 맞게 넣었기 때문에 오류가 없이 출력이 된다.
그러나 Ex5(vec = -3:10) 은 현재 threshold의 값을 따로 설정해주지 않았기 때문에 매개변수의 순서에 맞게 넣는게 아니다.
따라서 -3:10이 어떤 매개변수에 해당하는지 적어줘야한다.
다수의 매개변수, 기본값 예시
Ex6 = function(n, mu, sig, value = 0){
set.seed(100)
tmp = rnorm(n, mu, sig)
if(min(tmp) > value){
result = max(tmp) - min(tmp)
} else {
result = value - min(tmp)
}
return(result)
}
Ex6(4, 6, 3)
Ex6(4, 6, 3, 6)
연습하기
최솟값 찾기
# Find minimum by function ----
my.min = function(x){
mini = x[1]
for (i in 1:length(x)){
if (mini > x[i]){
mini = x[i]
} else {
mini = mini
}
}
return(mini)
}
set.seed(100)
x = runif(100, 0, 30)
my.min(x)
코드 설명
1. 첫 번째 값을 초기값으로 지정
2. 다음 값과 비교 후 더 작으면 그대로 유지
3. 만약 다음 값이 더 작을 경우 그 값으로 대체
4. 반복문을 이용하여 가장 작은 값 찾기
unif >>> 균등분포
팩토리얼
# Find Factorial
my.fac = function(n) {
if (n == 0) {
n = 1
} else{
n = n * my.fac(n - 1)
}
return(n)
}
my.fac(8) == factorial(8)
사용자 정의 함수는 함수 안에서 사용자 정의 함수를 사용할 수 있다.
ex)
ft1 = function(x){n = n*ft1(n-1)}
파이썬의 재귀함수를 생각하면 쉽게 이해할 수 있다.
연습문제
Q1 > f(x,y) = x^2 + y^2
Q2 > x값이 주어졌을 때 x값이 양수이면 x를 출력하고 양수가 아니면 x의 절댓값을 출력하는 함수
Q3 > n값이 주어졌을 때 N(5,2)에서 n개의 값을 뽑은 벡터의 최솟값과 최댓값의 합을 산출하는 함수
# for 문 (for loop/statement) 형식
for (<var> in <interval>) { <repeated_work> }
# 설정한 변수 <var>가 지정된 구간 <interval>에서 변하면서
# 문장 <repeated_work>을 반복실행
# 반복문; for loop ----
for (i in 1:3) {
print(i)
}
for (i in c("a", "b", "c")){
print(i)
}
for(i in 5:3){
print(i)
}
# 반복문 : 1~1000합 구하기 ----
sss = 0
for(i in 1:100){
sss = sss + i
}
## exercise ----
x = 3
for(i in 1:5){
x = x*2
}
sss = 0
for(i in 100:200){
sss = sss + i
}
kk = 1
for(i in 1:10){
kk = kk*i
}
kk == factorial(10)
# 반복문: 정규분포 ----
vec = rnorm(100,7,3)
sum1 = 0
for(i in 1:length(vec)){
sum1 = sum1 + vec[i]
}
m = sum1/length(vec)
## exercise ----
vec2 = rnorm(100, 5, 2)
sum2 = 0
for(i in 1:length(vec2)){
sum2 = sum2 + vec2[i]
}
m2 = sum2/length(vec2)
sum3 = 0
for(i in 1:length(vec2)){
sum3 = sum3 + vec2[i]^2
}
var1 = (sum3 - length(vec2)*m2^2)/(length(vec2)-1)
var1
R에서의 반복문은 파이썬에서의 반복문과 조금 다를 뿐 원리는 비슷함.
WHILE문
# while문(while loop/statement)
while(<condition>) { <repeated_work> }
# 반복할 조건 <condition>의 참 거짓을 판별하여
# 참인 경우 문장 <repeated_work>을 반복 실행
# 주어진 조건을 만족하는 동안 무한 반복하기 때문에 예상과 달리 루프에 갇히게 되면 break해야함.
# 반복문: while문 ----
x = 3
while(x<1000){
x = x*2
}
print(x)
# 결과가 다르다는 걸 느끼기
# 1
i = 0
sss = 0
while(i <= 100){
i = i + 1
sss = sss + i
}
sss # 5151
# 2
i = 0; sss = 0
while(i <= 99){
i = i + 1
sss = sss + i
}
sss # 5050
# 3
i = 0; sss = 0
while(i <= 100){
sss = sss + i
i = i + 1
}
sss # 5050
# 100~200합 구하기
i = 100
sss = 0
while(i <= 200){
sss = sss + i
i = i + 1
}
sss
# 1부터 10까지의 곱과 factorial 비교
i = 1
sss = 1
while(i <= 10){
sss = sss*i
i = i + 1
}
sss == factorial(10)
# example
# 처음으로 합이 100을 넘기는 n값 찾기
n = 0 ; n.sum = 0
while(n.sum <= 100){
n = n + 1
n.sum = n.sum + n
}
## practice ----
n = 0
while(n.sum <= 100000){
n = n + 1
n.sum = n.sum + n
}
n = 0
n.fac = 1
while(n.fac <= 1000000){
n = n + 1
n.fac = n.fac * n
}
repeat문
# repeat문
repeat{<repeated_work>}
# 작업 <repeated_work>을 무한 반복하다가 break 조건을 만족하면 stop
# 반복문: repeat ----
n = 0
sss = 0
repeat{
n = n + 1
sss = sss + n
if (n >= 100) break
}
# 이산확률분포 - random number 활용
x = 0:n
y = dbinom(x, n, p)
plot(x,y,
type = "h", xlim = c(0,n), lwd = 3, col = "tomato")
# 추출하는 난수의 개수 조정
n = 25
p = 0.2
random.x10 = rbinom(10, n, p)
plot(table(random.x10), xlim = c(0,n),
lwd = 3, col = "red")
mean(random.x10) ; var(random.x10)
random.x100 = rbinom(100, n, p)
plot(table(random.x100), xlim = c(0,n),
lwd = 3, col = "red")
mean(random.x100) ; var(random.x100)
random.x1000 = rbinom(1000, n, p)
plot(table(random.x1000), xlim = c(0,n),
lwd = 3, col = "red")
mean(random.x1000) ; var(random.x1000)
result = data.frame(n = c(10, 100, 1000),
mean = c(NA),
var = c(NA))
result[1,2:3] = c(mean(random.x10), var(random.x10))
result[2,2:3] = c(mean(random.x100), var(random.x100))
result[3,2:3] = c(mean(random.x1000), var(random.x1000))
result
추출하는 개수가 높아질수록 이론적인 평균값에 가까워진다는 것을 확인할 수 있음.
연속확률분포
## 연속확률분포 ----
### 정규분포 ----
rnorm(10, mean = 0, sd = 1)
random.x = rnorm(100)
mean(random.x) ; var(random.x)
# random number로 hist/curve 그리기
?hist
hist(random.x, probability = T, main = "Normal(0,1)")
# random number로 hist/curve 그리기
hist(random.x, probability = T, main = "Normal(0,1)")
# probability = T에 대한 의미 ----
# probability = T >> 상대도수
# probability = F >> 빈도수
curve(dnorm(x), add = T, col ="tomato", lwd = 3)
t-분포
### t-분포 ----
set.seed(123)
random.x = rt(100, 2.5)
hist(random.x, probability = T, main = "t-dist")
result = data.frame(
n = c(30, 50, 100, 2000),
mean = c(NA),
variance = c(NA)
)
x30 = rt(result[1,1], 2.5)
x50 = rt(result[2,1], 2.5)
x100 = rt(result[3,1], 2.5)
x2000 = rt(result[4,1], 2.5)
result
set.seed(123)
result[1,2:3] = c(mean(x30), var(x30))
result[2,2:3] = c(mean(x50), var(x50))
result[3,2:3] = c(mean(x100), var(x100))
result[4,2:3] = c(mean(x2000), var(x2000))
result = rbind(c(NA, 0, 2.5/(2.5-2)), result)
result