데이터를 시각화 하기 전에 파일 불러오기
setwd("C:\\Users\\user\\OneDrive - 경북대학교\\통계학과\\1-2\\R프로그래밍 및 실험")
#1
dat1 = read.csv("w7_2 csv.csv") # 띄어쓰기를 .으로 구분함
#2
dat1 = readr::read_csv("w7_2 csv.csv") # 띄어쓰기 있는 곳은 ``으로 묶어서 표기
시각화를 통해 데이터 분포 확인
히스토그램
hist(dat1$나이)
기호에 따라서 히스토그램을 더 보기 좋게 만들 수 있음.
hist(dat1$나이, main = "예제데이터의 나이(1)",
xlab = "age", ylab = "빈도")
# x축의 이름: xlab
# y축의 이름: ylab
hist(dat1$나이, main = "예제데이터의 나이(2)",
xlab = "age", ylab = "빈도", breaks = 10)
# break를 통해 그래프를 더 나누어줄 수 있음.
산점도
plot(x = dat1$나이, y = dat1$`성취도 점수`) # 기본적인 형태
plot(x = dat1$나이, y = dat1$`성취도 점수`,
main = "나이에 대한 성취도", xlab = "나이",
ylab = "성취도") # 알아보기 쉽게 만듦.
plot (formula = `성취도 점수`~`나이`, data = dat1,
main = "나이에 대한 성취도", xlab = "나이",
ylab = "성취도") # 2번째와 똑같은 그래프인데, 형태가 다름.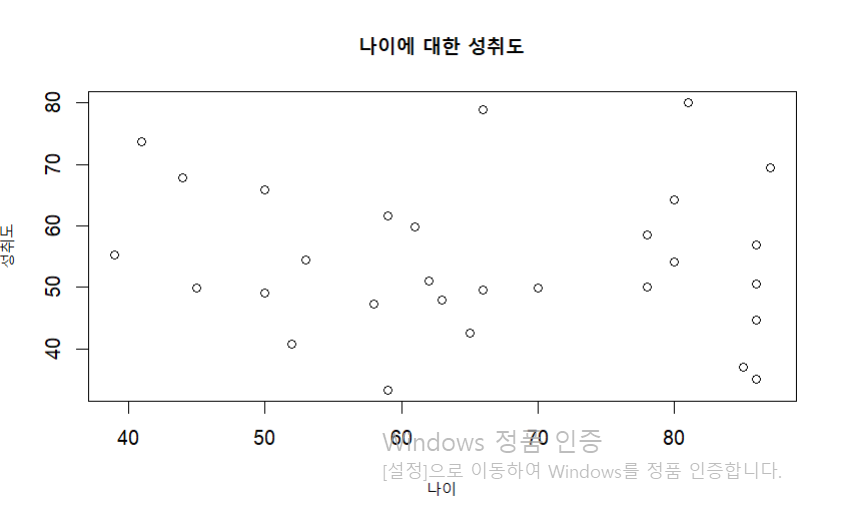
plot(formula = `우울 점수`~`나이`, data = dat1,
main = "나이에 대한 우울 점수", xlab = "나이",
ylab = "우울 점수",
col = c("red", "blue")[factor(성별)], cex = 1.5,
pch = c(20, 18)[factor(성별)])
# col 색 변경 / pch 점 모양 / cex 점 크기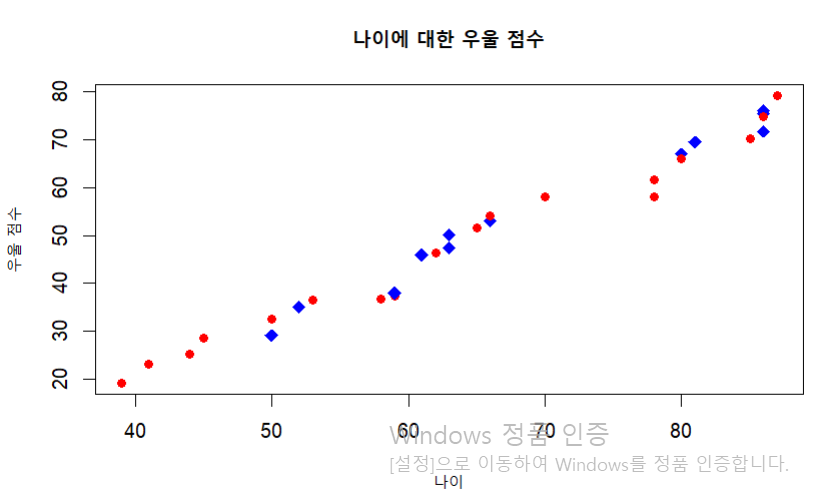
직선 추가하기
# y = a+bx
abline(a = -20, b = 1,
col = "dark green", lty = "dotted", lwd = 2.0)
# y = h
abline(h = 40,
col = "dark red", lty = "dotted", lwd = 2.0)
# x = v
abline(v = 50,
col = "dark blue", lty = "dotted", lwd = 2.0)
# 평활 직선
lines(stats::lowess(x = dat1$나이, y = dat1$`우울 점수`),
col = "dark red")
h = horizontal line
v = vertical line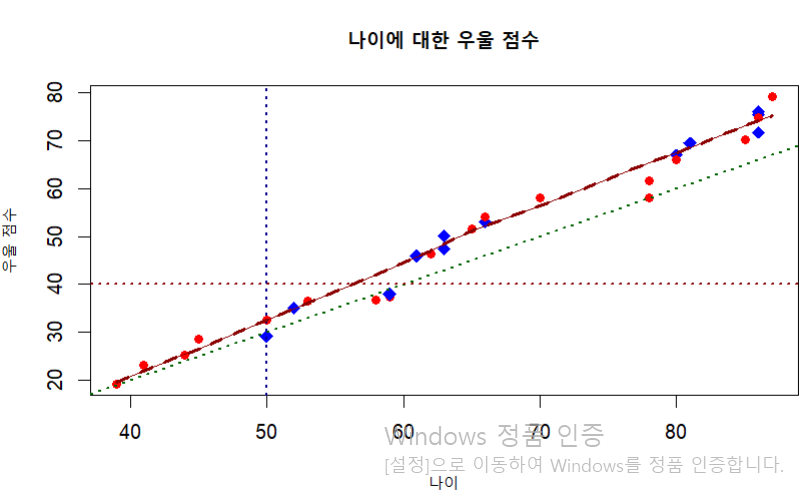
참고
지수평활법
가장 최근 데이터에 가장 큰 가중치가 주어지고 시간이 지남에 따라(과거로 갈수록) 가중치가 기하학적으로 감소되는 가중치 이동 평균 예측 기법의 하나. 데이터들이 시간의 지수 함수에 따라 가중치를 가지므로 지수 평활법이라고 한다. 이 기법은 가장 최근의 예측 데이터와 주요 판매 데이터 간의 차이에 적합한 평활 상수를 사용함으로써 과거의 데이터를 유지할 필요성을 갖지 않는다. 이러한 접근 방법은 어떤 추세를 갖지 않거나 계절적인 패턴을 나타내는 데이터 또는 추세와 계절성을 모두 갖는 데이터에 사용될 수 있다.
[네이버 지식백과] 지수 평활법 [exponential smoothing, 指數平滑法] (IT용어사전, 한국정보통신기술협회)
'프로그래밍 > R프로그래밍' 카테고리의 다른 글
| R프로그래밍 - 분포 관련 함수 (0) | 2023.11.08 |
|---|---|
| R프로그래밍 - 이산확률분포, 연속확률분포 (0) | 2023.11.08 |
| R 프로그래밍 - sort, group (2) | 2023.10.23 |
| R 프로그래밍 - 행렬 계산 (0) | 2023.10.22 |
| R 프로그래밍 - 데이터 구조 (array, list, data.frame) (1) | 2023.10.22 |