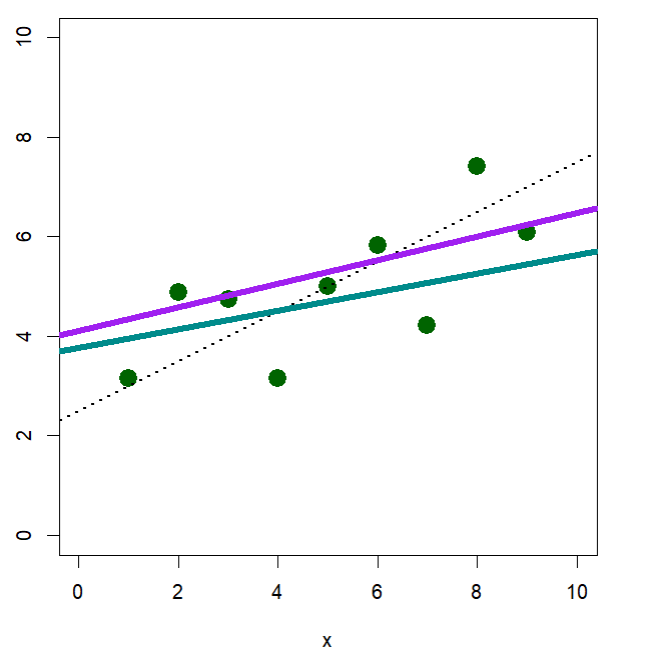
문자 선언
//문자 1개
char alpha = 'C';// 문자열 1개
char id[5] = "Nabi";
Nabi는 4글자인데 id[5]로 5글자를 저장하겠다고 코드를 작성하면
'N' 'a' 'b' 'i' '\0'로 저장이 된다.
// 문자열 3개
char fr[3][6] = {"Jaeil",
"Doori",
"Gosu"}
마찬가지로 행의 길이가 6글자로 저장된다고 했는데 5글자, 4글자로 문자열이 저장되어있다.
이 같은 경우에도 \0이 남는 자리에 저장이 된다.
원소 호출
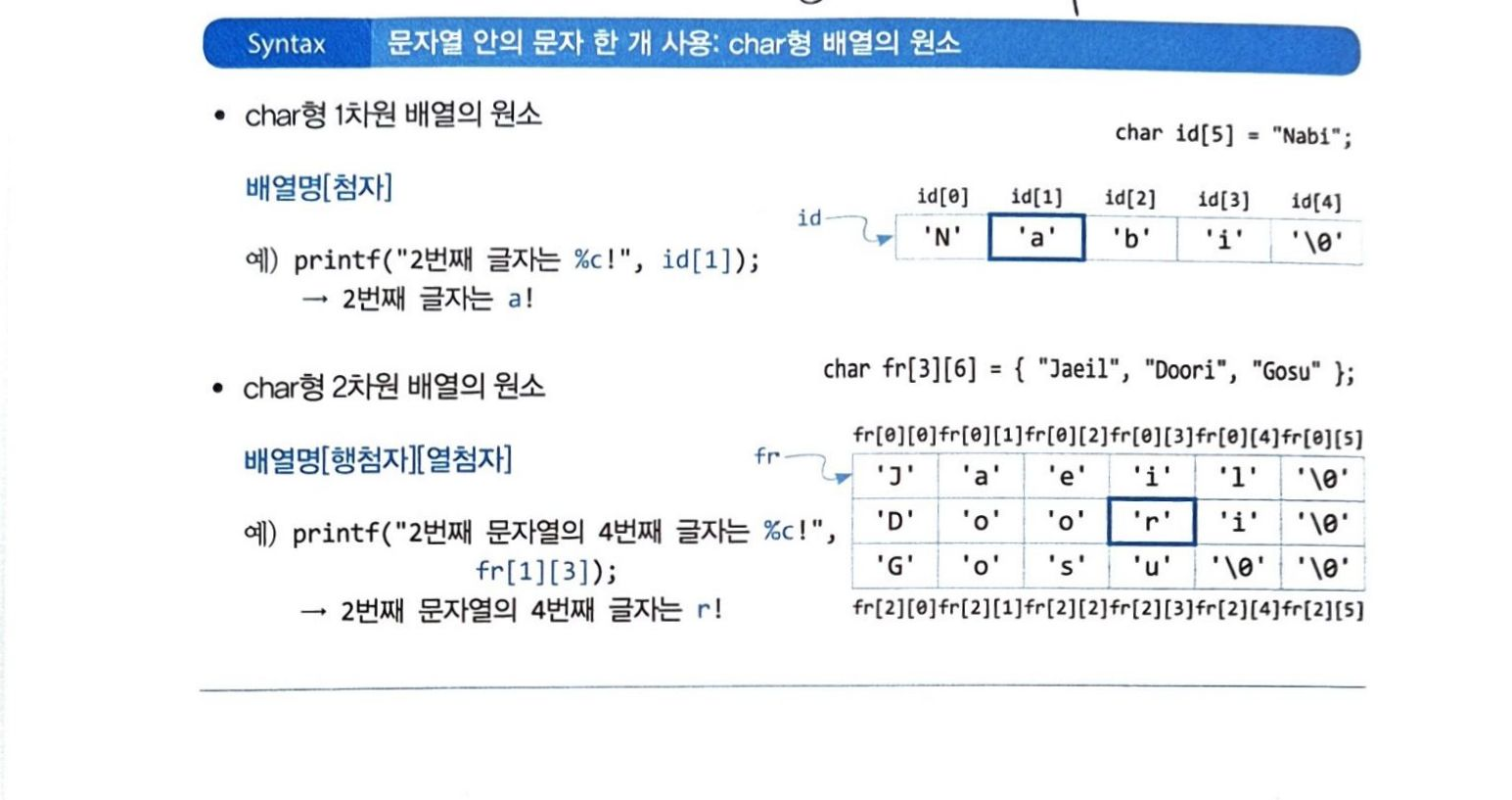
원소 호출을 할 때는 2차원 배열을 호출할 때 하는 것처럼 하면 된다.
문자열 단위의 입출력
문자열의 시작주소
char형 1차원 배열일 때
배열명: 문자열 시작 주소
// 문자열 1개
char id[5] = "Nabi";
id: 문자열 시작 주소 (포인터)
char형 2차원 배열일 때
배열명[행첨자] : 해당 행 문자열 시작 주소
// 문자열 3개
char fr[3][6] = {"Jaeil",
"Doori",
"Gosu"}
- fr[0] : 1번째 문자열 시작 주소
- fr[1] : 2번째 문자열 시작 주소
- fr[2] : 3번째 문자열 시작 주소
기억!!
배열명은 배열 시작 주소이며 배열 시작 위치를 가리킨다!
단순 문자열을 출력하기 위한 형식
문자열 입력
scanf("%s", 문자열 저장 시작 주소);
- 키보드에서 입력되는 문자열을 지정한 주소의 기억장소부터 차례대로 저장함.
- 배열에 남는 공간이 있어야 입력 문자열 뒤에 널 문자가 저장됨.
- ex) scanf("%s", id); , scanf("%s", fr[2]) (+&가 없다!)
문자열 출력
printf("%s", 문자열이 저장된 시작 주소);
- 시작 주소로부터 저장된 문자를 연속으로 출력하되 널 문자를 만나면 출력을 끝냄.
- ex) printf("%s", id);, printf("%s", fr[2])
주의!
문자열 시작 주소와 %를 이용한 문자열 출력은 널 문자('\0')를 만나야 출력이 끝난다.
다음 sur 배열은 배열 원소 수가 문자열의 길이 즉, 실제 문자 개수와 똑같다.
그러므로 널 문자가 저장되지 않기에 이상한 결과가 나올 수 있다.

참고로, 비주얼 스튜디오에서 위의 코드를 '*.c'와 같이 C언어 소스 파일로 저장하면 실행이 된다.
하지만 C++언어는 배열에 널 문자가 들어갈 공간이 없으면 오류가 되어 실행 자체가 되지 않는다.
문자열 처리 함수
strcpy() - 문자열 복사

strcmp() - 두 문자열의 크기를 비교



공백이 있는 문자열 입력

예시1
#include <stdio.h>
#include <string.h>
#pragma warning(disable: 4996)
#pragma warning(disable: 6031)
int main()
{
char grade, name[10], reply[10];
char correct[10] = "로딩중";
printf("받고 싶은 C언어 등급은? ");
scanf("%s", &grade);
printf("\n%c를 받기 위해 노력 중이군요!", grade);
printf("\n이름은? ");
scanf("%s", &name);
printf("%s님 반갑습니다!", name);
printf("\n문제: 세상에서 가장 느린 중학교는? ");
scanf("%s", &reply);
if (strcmp(reply, correct) == 0)
{
printf("맞았습니다!");
}
else
{
printf("틀렸습니다! 정답은 %s!\n", correct);
}
return 0;
}
예시2
#include <stdio.h>
#include <string.h>
#pragma warning(disable: 4996)
#pragma warning(disable: 6031)
#define N 5
int main()
{
char std[N][10] = { "최고수", "진재일", "강인", "나태희", "유명인" };
int i, quiz[N] = { 10, 9, 8, 7, 9 };
for (i = 0; i < N; i++)
{
printf("%s %d\n", std[i], quiz[i]);
}
return 0;
}
예시3
#include <stdio.h>
#include <string.h>
#pragma warning(disable: 4996)
#pragma warning(disable: 6031)
#define N 5
int main()
{
char std[N][6] = { "itsme", "ace", "iam", "myid", "snow"};
char input[6];
int i;
printf("아이디는? ");
scanf("%s", &input);
for (i = 0; i < N; i++)
{
if (strcmp(input,std[i]) == 0)
{
printf("%s님 반갑습니다.", input);
break;
}
}
if (i == N)
{
printf("없는 아이디입니다.");
}
return 0;
}'프로그래밍 > C,C++' 카테고리의 다른 글
| 포인터 (0) | 2024.06.06 |
|---|---|
| 다양한 함수와 변수의 참조 범위 (0) | 2024.05.30 |
| 인수 전달하는 함수 (0) | 2024.05.28 |
| 인수 전달하지 않는 함수 (0) | 2024.05.27 |
| 자료 배열 2 (9장) (0) | 2024.05.27 |