클래스 속성 사용하기
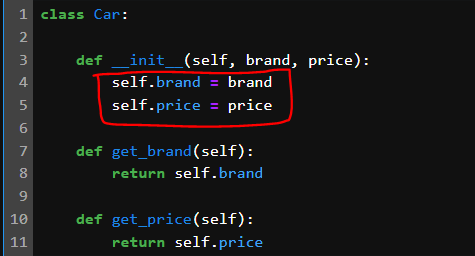
class Person:
backpack = []
def put_backpack(self, item):
self.backpack.append(item)
james = Person()
james.put_backpack('노트북')
maria = Person()
maria.put_backpack('파이썬')
print(james.backpack) # james는 Person 클래스 이기에 출력가능
print(maria.backpack) # maria는 Person 클래스 이기에 출력가능
> Person 클래스에 바로 backpack 속성을 넣고 put_backpack 메서드를 만든다.
> 그리고 인스턴스 2개를 만들고 각각 put_backpack 메서드 사용
> 클래스 속성은 클래스에 속해 있어서 모든 인스턴스에서 공유함.

그런데 앞의 코드는 한 가지 아쉬운 점이 있다.
put_backpack 메서드에서 클래스 속성 backpack에 접근할 때 self를 사용했는데
self는 현재 인스턴스를 뜻하므로 클래스 속성을 지칭하기에는 모호하다.
따라서 클래스 속성에 접근할 때는 다음과 같이 클래스 이름으로 직접 접근하면 코드가 더 명확해진다.
class Person:
backpack = []
def put_backpack(self, item):
Person.backpack.append(item)
james = Person()
james.put_backpack('노트북')
maria = Person()
maria.put_backpack('파이썬')
print(james.backpack)
print(maria.backpack)
위와 같이 코드를 입력하니 클래스 Person에 속한 backpack 속성이라는 것을 바로 알 수 있다.
마찬가지로 클래스 바깥에서도 다음과 같이 클래스 이름으로 클래스 속성에 접근하면 된다.
print(Person.backpack)
파이썬에서는 속성, 메서드 이름을 찾을 때 인스턴스, 클래스 순으로 찾는다.
그래서 인스턴스 속성이 없으면 클래스 속성을 찾게 되므로 james.backpack, maria.backpack도 문제없이 동작한다.
겉보기에는 인스턴스 속성을 사용하는 것 같지만 실제로는 클래스 속성이라는 것이다.
인스턴스와 클래스에서 __dict__ 속성을 출력해보면 현재 인스턴스와 클래스의 속성을 딕셔너리로 확인할 수 있다.
여기서 중요한 것!
backpack을 그럼 여러 사람이 공유하지 않도록 하기 위해서는 어떻게 해야하나?
그냥 backpack을 인스턴스 속성으로 만들면 된다.
어떻게 만드냐 앞에 있는 Person 클래스 코드에 __init__를 추가하여 초기화가 되도록 만들어주면 된다.
class Person: # 클래스이름
def __init__(self): # constructor
self.backpack = []
def put_backpack(self, item): # instance method
self.backpack.append(item)
james = Person() # object instanciation
james.put_backpack('노트북')
maria = Person() # object instanciation
maria.put_backpack('파이썬')
print(james.backpack) # 명확한 instance 변수 호출
print(maria.backpack) # 명확한 instance 변수 호출

> 여기서 확인해보면 각각 넣은 물건만 출력된다는 것을 알 수 있다.
> 즉, 인스턴스 속성은 인스턴스별로 독립되어 있으며 서로 영향을 주지 않는다.
정리
> 클래스 속성: 모든 인스턴스가 공유. 인스턴스 전체가 사용해야 하는 값을 저장할 때 사용
> 인스턴스 속성: 인스턴스 별로 독립되어 있음. 각 인스턴스가 값을 따로 저장해야할 때 사용
비공개 클래스 속성
> 클래스 속성을 만들 때 _속성과 같이 __(밑줄 2개)로 시작하면 비공개 속성이 된다.
> 클래스 안에서만 접근할 수 있고, 클래스 바깥에서는 접근할 수 없다.
class 클래스이름:
__ 속성 = 값 # 비공개 클래스 속성
class Boxing:
__item_limit = 10 # 비공개 클래스 속성
def print_item_limit(self):
print(Boxing.__item_limit)
peter = Boxing()
peter.print_item_limit()
print(Boxing.__item_limit) # 클래스 바깥에서는 접근할 수 없음.

정적메서드 사용하기
> 인스턴스를 통하지 않고 클래스에 바로 호출 가능
> 정적 메서드는 다음과 같이 메서드 위에 @staticmethod를 붙인다.
> 말 그대로 정적메서드이며 이때 정적메서드는 매개변수에 self를 지정하지 않는다.
class 클래스이름:
@staticmethod
def 메서드(매개변수1, 매개변수2):
코드
> @staticmethod처럼 앞에 @가 붙은 것을 데코레이터(장식자)라고 하며 메서드(함수)에 추가 기능을 구현할 때 사용
class Calculator:
@staticmethod
def add(x, y):
print(x + y)
@staticmethod
def mul(x, y):
print(x * y)
Calculator.add(10, 20)
Calculator.mul(10, 20)
> 정적 매서드는 self를 받지 않으므로 인스턴스 속성에는 접근할 수 없음.
> 그래서 정적 메서드는 인스턴스 속성, 인스턴스 메서드가 필요없을 때 사용함.
> 정적 메서는 메서드의 실행이 외부 상태에 영향을 끼치지 않는 순수 함수(pure function)를 만들 때 사용함.
> 순수 함수는 부수 효과(side effect)가 없고 입력값이 같으면 언제나 같은 출력값을 반환함.
> 즉, 정적 메서드는 인스턴스의 상태를 변화시키지 않는 메서드를 사용할 때 사용함.
클래스메서드 사용하기
> 클래스 메서드는 다음과 같이 메서드 위에 @classmethod를 붙임.
> 이때 클래스 메서드는 첫 번째 매개변수에 cls를 지정해야 한다.
class 클래스이름:
@classmethod
def 메서드(cls, 매개변수1, 매개변수2):
코드
class Car:
count = 0
def __init__(self):
Car.count += 1
@classmethod
def print_count(cls):
print(f"{cls.count}대가 생성되었습니다.") # cls로 클래스 속성에 접근
x = Car()
y = Car()
z = Car()
Car.print_count()
> 먼저 인스턴스가 만들어질 때마다 숫자를 세야하기에 __init__메서드에서 클래스 속성 count에 1을 더해줌.
> @classmethod를 붙여서 클래스 메서드를 만든다.
> 클래스 메서드는 첫 번째 매개변수가 cls인데 여기에는 현재 클래스가 들어온다.
> 따라서 cls.count처럼 cls로 클래스 속성 count에 접근할 수 있다. (정적 메서드와의 차이점)
> 클래스 메서드는 정적 메서드처럼 인스턴스 없이 호출할 수 있다는 점은 같다.
> 그러나 클래스 메서드는 메서드 안에서 클래스 속성, 클래스 메서드에 접근해야할 때 사용.
class Car:
count = 0
def __init__(self):
Car.count += 1
@classmethod
def print_count(cls):
print(f"{cls.count}대가 생성되었습니다.")
@classmethod
def create(cls):
instance = cls()
return instance
x = Car()
y = Car()
z = Car() # x, y, z 객체 생성으로 count 증가 (Car.count += 1)
w = x.create() # w 객체에서 classmethod 호출로 count 증가 (Car.count += 1)
o = Car.create() # Car클래스에서 직접 classmethod 호출로 count 증가 (Car.count += 1)
Car.print_count()
'프로그래밍 > Python' 카테고리의 다른 글
| 제너레이터(Generator) (0) | 2024.08.12 |
|---|---|
| Python - Closure 함수 (0) | 2023.12.15 |
| Python - 인스턴스 변수 vs 정적변수 (0) | 2023.11.25 |
| Python - 클래스 생성자 (2) | 2023.11.25 |
| Python - 클래스 (1) | 2023.11.25 |