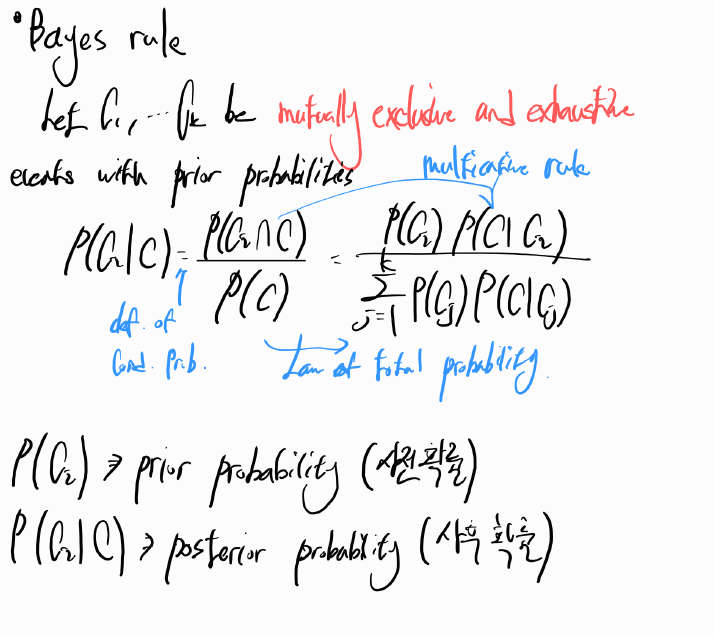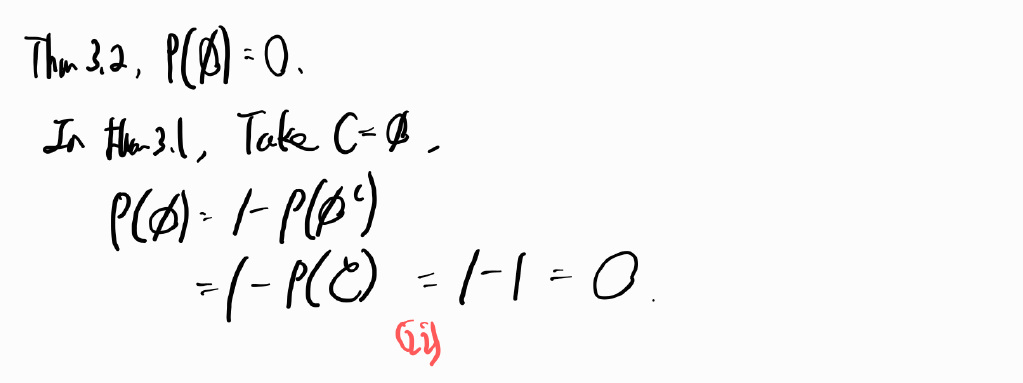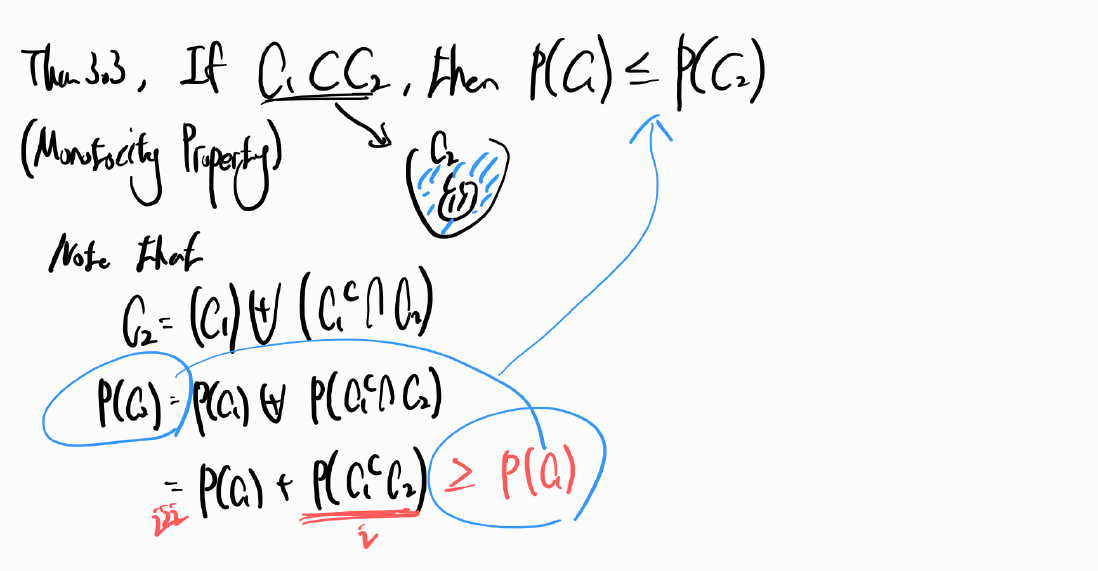(학부생이라 오류가 있을 수 있습니다. 댓글로 정정해서 남겨주시면 감사드리겠습니다.)
단순선형회귀는 input이 하나이고 이 input을 통해 y값을 예측하는 모형입니다.
input이 만약에 여러 개면 Mutiple linear regression이라고 하는데 이 부분은 다음 포스팅 때 다뤄보도록 하겠습니다.
단순선형회귀는 독립변수 하나와 종속변수의 관계를 관측할 수 있게 해주는 설명력이 높은 통계적 방법입니다.
회귀분석의 첫 단추를 끼우는 만큼 단순선형회귀에 대해 제가 배운 내용을 바탕으로 설명을 해보겠습니다.
Simple linear regression model
- The response variable $Y$ 와 the predictor variable $X$ 는 $$ Y = \beta_0 + \beta_1X + \epsilon $$, where $\epsilon$ is a random error with $E(\epsilon) = 0$. (Population 수준의 모델)
Simple regression model with the observed data
| Observation Number | Response Variable $Y$ | Predictor $X$ |
| 1 | $y_1$ | $x_1$ |
| 2 | $y_2$ | $x_2$ |
| . . . . |
. . . . |
. . . . |
| n | $y_n$ | $x_n$ |
- The regression model for the observed data is $$ y_i = \beta_0 +\beta_1x_i + \epsilon_i, i = 1, 2, ...., n$$, where $\epsilon_i$ represents the error in $y_i$.
Parameter estimation
- To estimate the unknown regression coefficients, $\beta_0$ and $\beta_1$, the ordinary least squares(OLS) method is commonly used.
- From the regression model, we can write $$\epsilon_i = y_i - \beta_0 - \beta_1x_i, i = 1, 2,.... , n.$$
- We estimate $\beta_0$ and $\beta_1$ by minimizing $$ S(\beta_0, \beta_1) = \displaystyle\sum_{i=1}^{n}{(y_i - \beta_0 - \beta_1x_1)^2}$$ >> 가장 오른쪽에 있는 식은 Convex function이어서 미분 최솟값 구하면 됩니다.
우리가 parameter 값을 구하고 싶은데, 현실은 observed data의 X와 Y값 만을 알고 있는 상태입니다.
그렇기 때문에 우리는 parameter 값을 추정하는 겁니다. 실제 X값과 Y값을 통해 구할 수 있는데,
추정은 다음과 같은 식을 통해 구할 수 있습니다.
OLS estimate
- It can be shown that the estimates of \beta_0 and \beta_1 that minimize $S(\beta_0, \beta_1)$ are given by $$\hat{\beta_1} = \frac{\sum_{i = 1}^{n}{(y_i - \overline{y})(x_i - \overline{x})}}{\sum_{i = 1}^{n}{(x_i - \overline{x})^2}}$$ and $$ \hat{\beta_0} = \overline{y} - \hat{\beta_1}\overline{x}$$
- $ \hat{\beta_0} = \overline{y} - \hat{\beta_1}\overline{x}$ 증명

- $\hat{\beta_1} = \frac{\sum_{i = 1}^{n}{(y_i - \overline{y})(x_i - \overline{x})}}{\sum_{i = 1}^{n}{(x_i - \overline{x})^2}}$ 증명
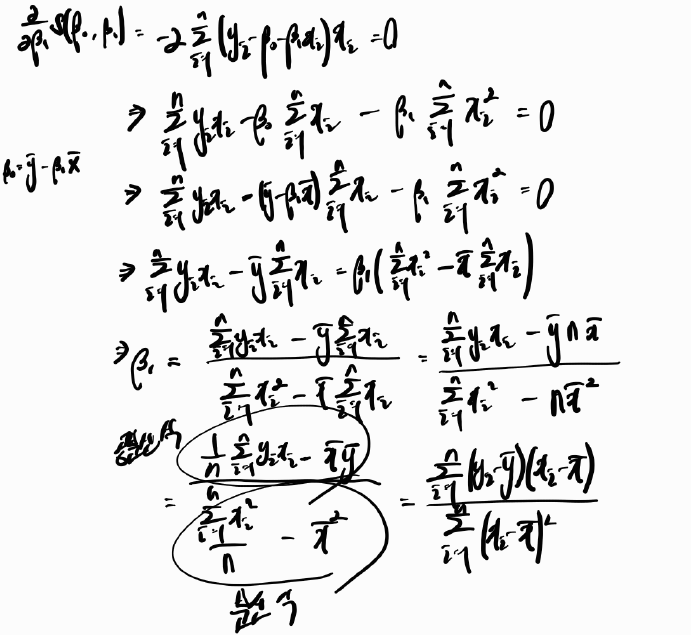
이렇게 하여 $\hat{\beta_0}$ 과 $\hat{\beta_1}$을 구할 수 있는데,
여기서 $\hat{}$ 을 취한 이유는 True 값(추정치가 아닌 값)을 모르고 추정치만 알고 있어서 $\hat{}$을 취했습니다.
Fitted values
- The OLS regression line is obtained as $$ \hat{Y} = \hat{\beta_0} + \hat{\beta_1}X $$.
- The $i$-th fitted value is given by $$ \hat{y_i} = \hat{\beta_0} + \hat{\beta_1}x_i, i = 1, 2, ..., n$$.
- Example.

이렇게 fitted 했다면 해석은 어떻게 해야 하는지 궁금할 수 있을 것 같은데요...
그런데 그 전에 $ Y = \beta_0 + \beta_1X + \epsilon $ 이 식 양변에 평균을 취하게 되면 다음과 같이 나옵니다.
$$ E(Y) = \beta_0 + \beta_1X$$.
왜 이렇게 나오냐면 $E(\beta_0 + \beta_1X + \epsilon)$ 에서 $ \beta_0 + \beta_1X $는 이미 값을 알고 있고 그렇기 때문에 상수로 처리됩니다. 그러면 자연스럽게 $ \beta_0 + \beta_1X + E(\epsilon)$ 이 되고, 회귀분석에서는 $E(\epsilon) = 0$이라고 하는 아주 중요한 가정이 있기에 자연스럽게 $E(Y) = \beta_0 + \beta_1X$ 이 식이 유도가 됩니다.
Interpertation of coefficients
- Recall that $$ E(Y) = \beta_0 + \beta_1X$$.
- $\beta_0$ is the expected value of $Y$ when $X = 0$.
- $\beta_1$ is the amount of increase in the expected value of $Y$ for every one-unit increase inn $X$. - For example E(minutes) = 4.162 + 15.509 $\times$ Units.
- The average length of calls is the 4.162 minutes when no component needs to be repaired.
- The average length of calls increases by 15.509 minutes for each additional component that has to be repaired.
Test of hypothesis
- In the simple linear regression analysis, the usefulness of the predictor(= X) can be tested by using the following hypothesis test:
$H_0: \beta_1 = 0 versus H_1: \beta_1 \neq 0$.
(X와 Y의 linear relationship을 $\beta_1$을 체크하여 확인할 수 있습니다.)
(주의할 점: $\hat{\beta_1}$을 이용해서 가설검정을 하는 것이 아닙니다.) - To this end, we need to further assume that

이렇게 간단한 식에 4가지의 가정이 들어가있습니다. 중요하기에 반드시 알아두는게 좋다고 합니다.
1. $E(\epsilon_i) = 0$
2. $Var(\epsilon_i) = \sigma^2$
3. $\epsilon_i$ ~ Normal
4. $\epsilon_1, ..... \epsilon_n$ are independent.
T-test
- Under $H_0$ : $\beta_1 = 0$, it can be shown that $$ T = \frac{\hat{\beta_1}}{s.e.(\hat{\beta_1})}$$ follows a Student's t distribution with n - 2 degrees of freedom, where $$ s.e.(\hat{\beta_1}) = \sqrt{\frac{\sum_{i=1}^{n}{(y_i - \hat{y_i})^2/(n-2)}}{\sum_{i=1}^{n}{(x_i - \overline{x})^2}}}$$.
Using t-distribution, we can compute the p-value. At significant level $\alpha = 0.05$, we reject $H_0$ if the p-value $\leq$ 0.05. Otherwise, we fail to reject $H_0$.
보통은 모델이 유용하기를 바라기 때문에 귀무가설을 기각하기를 원합니다.
앞서말한 계수들 뿐만 아니라 $\sigma^2$를 추정하는 것도 중요한데요
바로 error의 변동성을 설명하기 위함입니다.
Estimation of $\sigma^2$
- Define $$ e_i = y_i - \hat{y_i}, i = 1, 2, .... , n $$ which are called the residuals.
이렇게 하는 이유는 $\epsilon_i = y_i - \beta_0 - \beta_1x_i$를 - We can estimate $\sigma^2$ by using $$ \hat{\sigma^2} = \frac{\sum_{i=1}^{n}{e_i^2}}{n - 2} = \frac{\sum_{i=1}{n}{(y_i - \hat{y_i})^2}}{n-2} \equiv $$ MSE,
where $\sum_{i=1}{n}{(y_i - \hat{y_i})^2}$ is referred to as SSE (Sum of Squares of Errors) and n -2 is called the df(degrees of freedom).
여기서 n은 전체 데이터이고 2는 추정치의 개수입니다. 추정치는 $\beta_0, \beta_1$으로 2개가 존재했습니다. 그렇기에 2를 빼주는 것입니다.
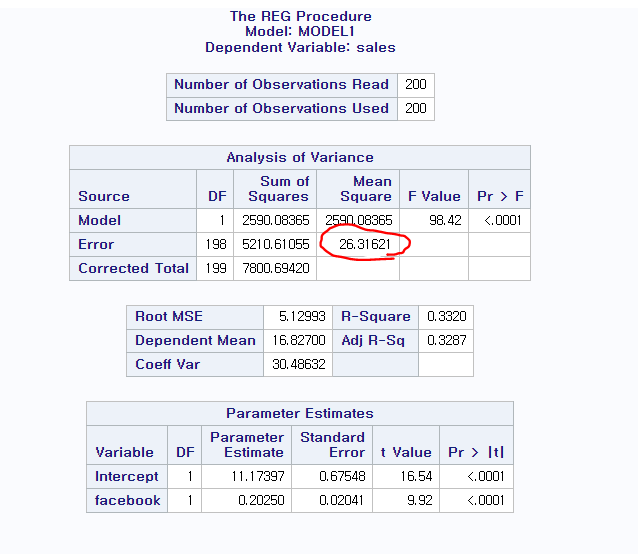
SAS라는 통계 프로그램을 통해서 MSE를 관측할 수 있는데 밑에 그림의 빨간색 부분이 MSE입니다.
MSE in SAS
Confidence intervals
- The (1 - $\alpha$) $\times$ 100% confidence intervals (or limits) for $\beta_0 and \beta_1$ are given by $$ \hat{\beta_0} \pm t_{n-2,\alpha/2} \times s.e.(\hat{\beta_1})$$,
where $t_{n-2, \alpha/2}$ is the (1 - $\alpha$ / 2) percentile of a t - distribution with n - 2 df
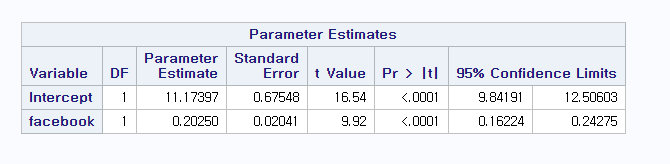
이렇게 신뢰구간도 설정하고 회귀모델을 fitting 했으면 이제 예측을 해봅시다
(예측은 크게 설명력과 예측력으로 구분할 수 있습니다.)
Prediction
- There are two types of predictions:
1. Prediction of the value of Y given X, i.e., $Y = \beta_0 + \beta_1X + \epsilon$.
2. Prediction of the mean of Y given X, i.e., $E(Y) = \beta_0 + \beta_1X$.
여기서 하나 알아갈 수 있는 점은 confidence interval은 prediction of the value of Y given X가 넓을 수 밖에 없습니다. 왜냐하면 $\epsilon$, 즉, error가 포함되어 있기 때문입니다.
- Given $X = x_0$,
- in the first case, the predicted value is $\hat{y_0} = \hat{\beta_0} + \hat{\beta_1}x_0$.
- in the second case, the mean response is $\hat{\mu_0} = \hat{\beta_0} + \hat{\beta_1}x_0$.
Prediction intervals
- The (1 - $\alpha$) $\times$ 1000% prediction limits are given by $$\hat{\mu_0} \pm t_{n-2,\alpha/2} \times s.e.(\hat{\mu_0})$$ and $$\hat{y_0} \pm t_{n-2, \alpha/2} \times s.e.(\hat{y_0})$$,
where $$s.e.(\hat{\mu_0}) = \hat{\sigma}\sqrt{\frac{1}{n} + \frac{(x_0 - \overline{x})^2}{\sum_{i=1}^{n}{(x_i -\overline{x})^2}}}$$ and $$ s.e.(\hat{y_0}) = \hat{\sigma}\sqrt{1+ \frac{1}{n} + \frac{(x_0 - \overline{x})^2}{\sum_{i=1}^{n}{(x_i -\overline{x})^2}}} $$
(여기서 보면 Expected value와 value 값의 interval을 측정할 때 차이점이 보입니다. 바로 1이 더해졌냐 안 더해졌냐인데요. value값은 아까 Prediction 파트에서 value값의 confidence interval이 넓을 수 밖에 없다고 한 것과 비슷한 매락의 이야기입니다. $\sigma^2$은 $\epsilon$의 분산이고 $\epsilon$만큼 더해진 것을 확인할 수 있습니다. 그렇기에 더 넓은 confidence interval을 가질 수 밖에 없다고 설명한 것입니다.)
Role of $\sigma^2$
- 분산이 크다는 것은 값들이 선에 비교적 가깝지 않고, 분산이 작다는 것은 선에 비교적 선에 가깝다는 얘기입니다.
- 그러나 분산 즉, $\sigma$의 분산만을 가지고는 선형성을 추론하기에 어려움이 있습니다. 가령, 범위가 다를 때는 $\sigma$의 분산으로 선형성을 추론하면 오류가 발생할 수 있습니다.
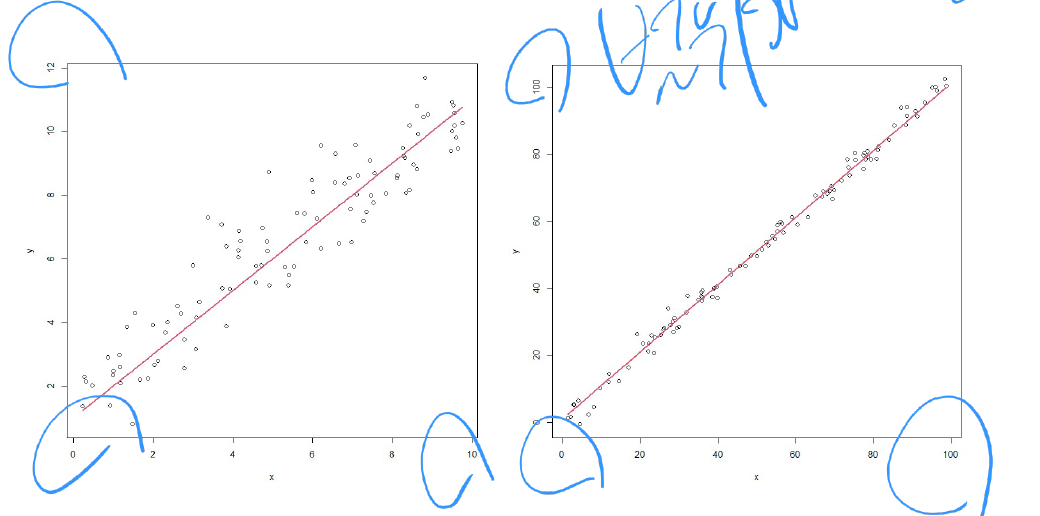
그래서 이 상황에서 고안된 것이
Measuring the strength of the linear relationship
- To remedy the limitation of $\sigma^2$, we can propose to use $$\frac{\sigma^2}{Var(Y)}$$, since it decreases if $\sigma^2$ decreases or $Var(Y)$ increases.
- 우리는 $\sigma^2$의 값을 모르기 때문에 $\sigma^2$의 추정치인 MSE를 사용할 것입니다. 복습을 하자면 $$MSE = \frac{\sum_{i=1}^{n}{(y_i-\hat{y_i})^2}}{n-2}$$ 이고 $Var(Y)$도 모르기 때문에 추정치인 $\hat{Var}(Y)$을 사용할 것입니다. 이것도 다시 remind 하자면 $$ \hat{Var}(Y) = \frac{\sum_{i=1}^{n}{(y_i-\overline{y})^2}}{n-1} $$ 입니다.
여기서 선형성인 것을 나타내주는 지표인 결정계수가 나옵니다.
$R^2$
- To measure the strength of the linear relationship, we define the so-called $R^2$ as follows:
$$R^2 = 1 - \frac{\sum_{i=1}{n}{(y_i - \hat{y_i})^2}}{\sum_{i=1}{n}{(y_i-\overline{y})^2}} = 1 - \frac{SSE}{SST}$$
where SST stands for the total sum of squared deviation in $Y$ from its mean.
Property of $R^2$
- It can be shown that $$\displaystyle\sum_{i=1}^{n}{(y_i - \overline{y})^2} = \displaystyle\sum_{i=1}^{n}{(\hat{y_i}-\overline{y})^2} + \displaystyle\sum_{i=1}^{n}{(y_i - \hat{y_i})^2}$$
where 왼쪽 식에서 첫 번째 식은 SSR(the sum of squares due to regression)으로 불린다.
That is, $$SST = SSR + SSE$$. - This implies that $$0 \leq R^2 \leq 1$$
(그 이유는 $R^2 = SSR/SST$ and $0 \leq SSR \leq SST$).
'통계학 > 회귀분석(Regression Analysis)' 카테고리의 다른 글
| Matrix format (0) | 2025.02.18 |
|---|---|
| Qualitative variables as predictors (0) | 2024.11.22 |
| Transformation of variables (0) | 2024.11.19 |
| 다중선형회귀 (Multiple linear regression) (0) | 2024.10.06 |