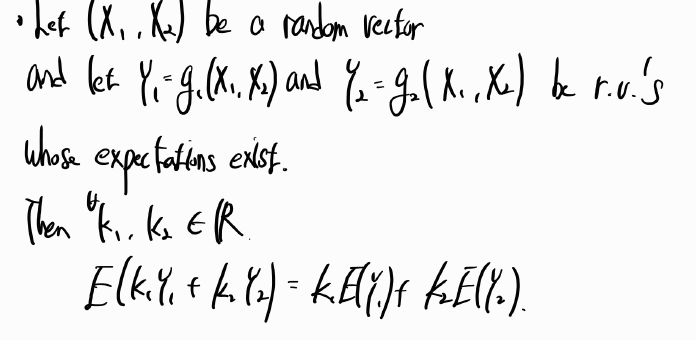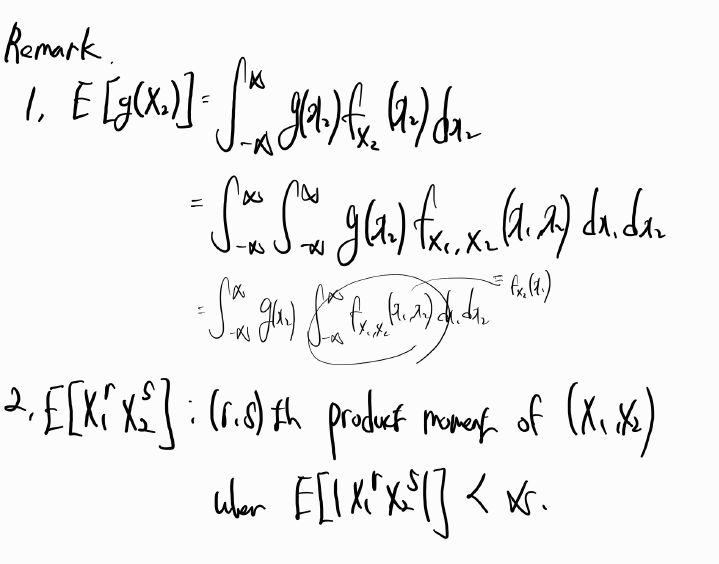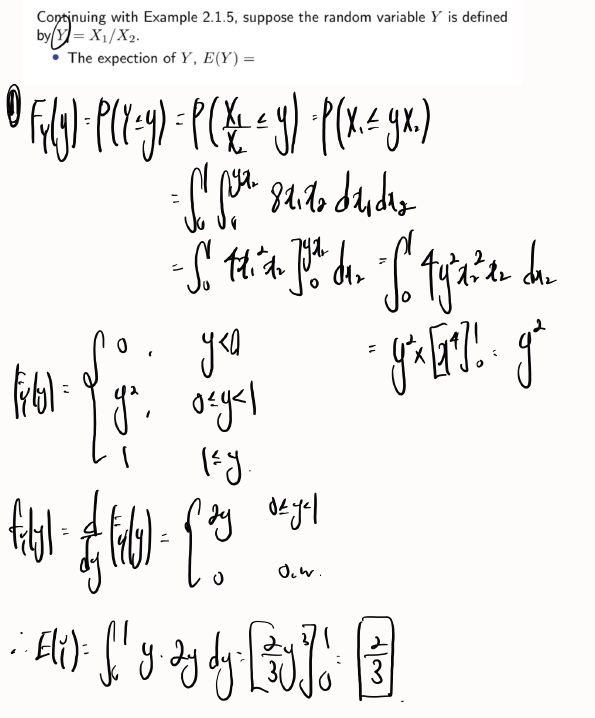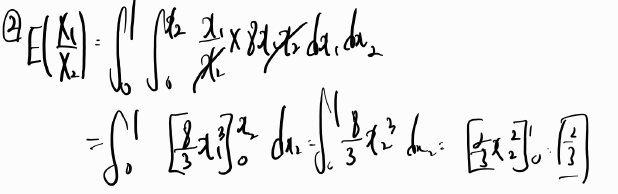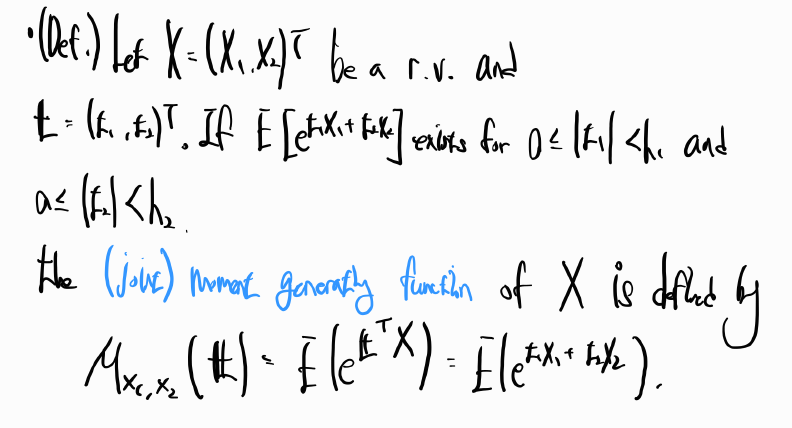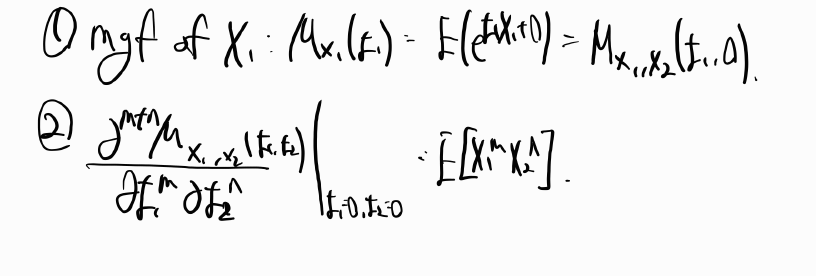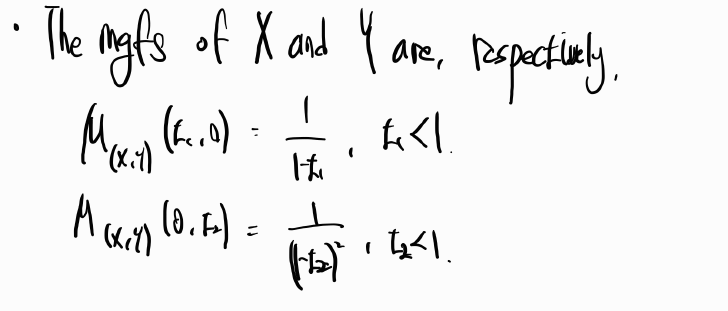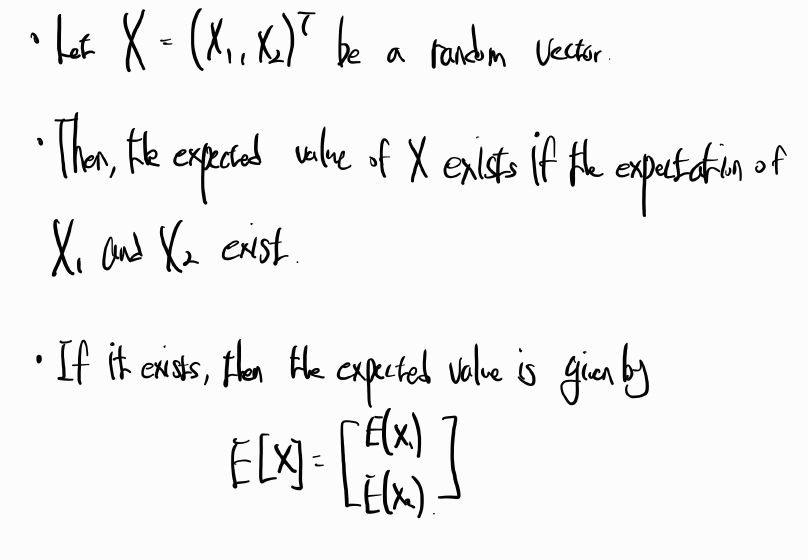Sales = β0 + β1youtube + β2facebook + β3newspaper + ϵi
Q1. Write the assumptions we impose on ϵ
>> ϵ ~ iid N(0, σ2)
Q2. Using the OLS method, estimate regression coefficients.
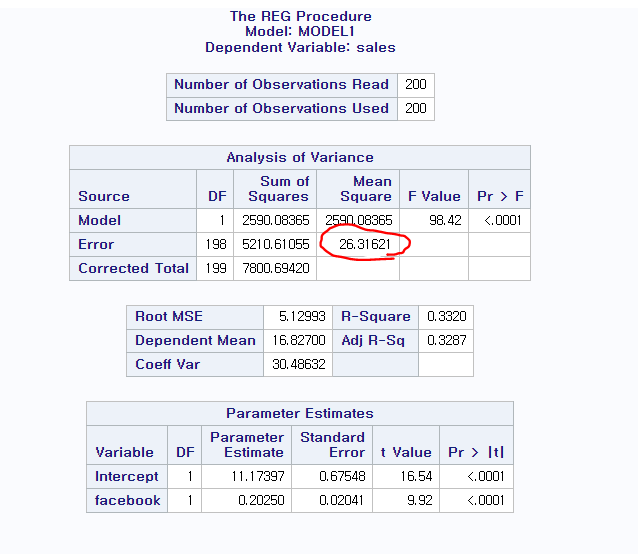
^β0 = 3.52667
^β1 = 0.04576
^β2 = 0.18853
^β3 = -0.00104
Q3. Estimate σ2
4.09096
없으면 root MSE 제곱해서 답 적기(2.022612)
SSE / DF = MSE
Q4. Test the overall utility of the model.
H0:β1=β2=β3=0
H1:βj≠0 for some j = 1,2,3
Let α=0.05
Since p-value =< 0.0001 is less than α=0.05, we reject H0.
Thus, the overall model is useful.
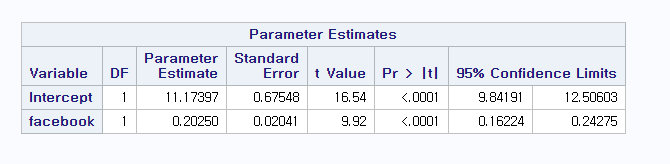
Q5. Can we claim that the facebook advertising is related to sales? Justify.
H0:β2=0
H1:β2≠0
Let α = 0.05.
Since p-value =< 0.0001 is less than α = 0.05, we reject H0.
That is, we can claim that the facebook advertising is related to sales.
Q5-1. Can we claim that the newspaper advertising is related to sales? Justify.
H0: β3=0
H1: β3≠0
Let α = 0.05.
Since p-value = 0.8599 is greater than α = 0.05, we fail to reject H0.
That is, we can claim that the facebook advertising is related to sales.
This means that the newspaper advertising is not related to sales.
Q6. Compute the expected change in the sales when our spending for youtube advertisement increases by 1000달러 while the others are fixed.
45.76달러(0.04576 * 1000달러)
Q7. Compute the expected sale when we spend 1000달러 for each method of adv.
^Sale
45.76 + 188.53 + 3526.67 - 1.04= 3.7599 * 1000
Q7-1. Compute the expected sale when we spend 0달러 for all of adv.
x들의 값이 0일 때의 기댓값이 위의 질문에 대한 대답
β0 => 3.52667 * 1000달러
β0는 실제의 데이터 변수의 성질에 따라 x들의 값을 0으로 둘 수 있는지 없는지가 갈린다.
Q8. Can we argue that youtube is negatively related to the sale?
1. youtube랑 sales와 관계가 있는지부터 확인(β)
2. 그러고 난 다음에 관계가 있으면 ˆβ의 값을 신뢰할 수 있음.
왜냐하면 β1의 값이 0이 아니라고 1번에서 결론지었기 때문에
We conclude that β1≠0.
However, since ^β1 = 0.04576 is greater than 0, we cannot argue that...
Q8-1. Can we argue that newspaper is negatively related to the sale?
We conclude that β3 = 0. We cannot argue that ...
Q9. Compute the R-squared and interpret it.
R2 = 0.8972
89.72% variability in sales can be explained
by the fitted model (with youtube, facebook, and newspaper.)
Q9-1. adj. R-squared 도 마찬가지.
'통계학 > 회귀분석(Regression Analysis)' 카테고리의 다른 글
| Matrix format (0) | 2025.02.18 |
|---|---|
| Qualitative variables as predictors (0) | 2024.11.22 |
| Transformation of variables (0) | 2024.11.19 |
| 단순선형회귀 (Simple linear regression) (3) | 2024.09.25 |