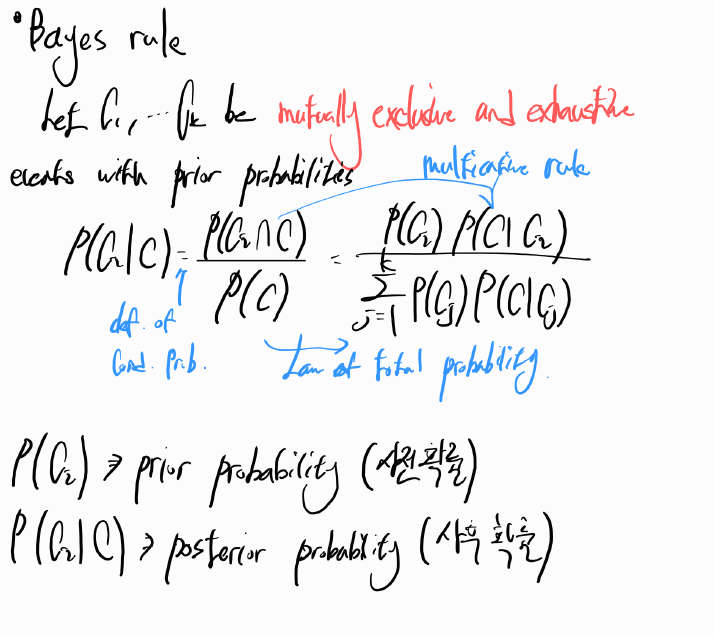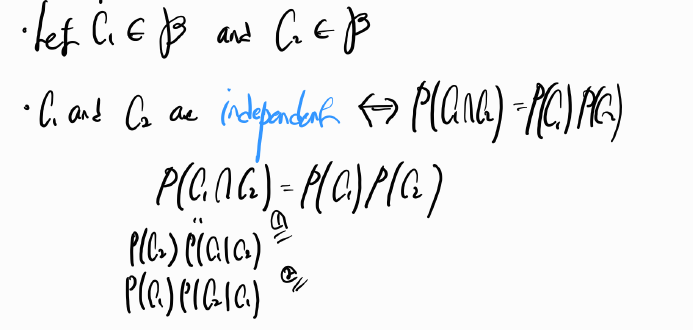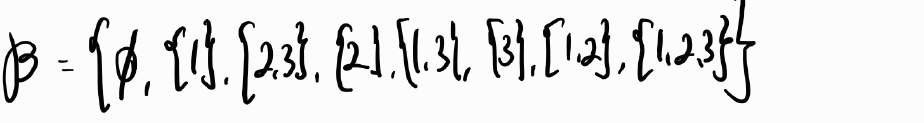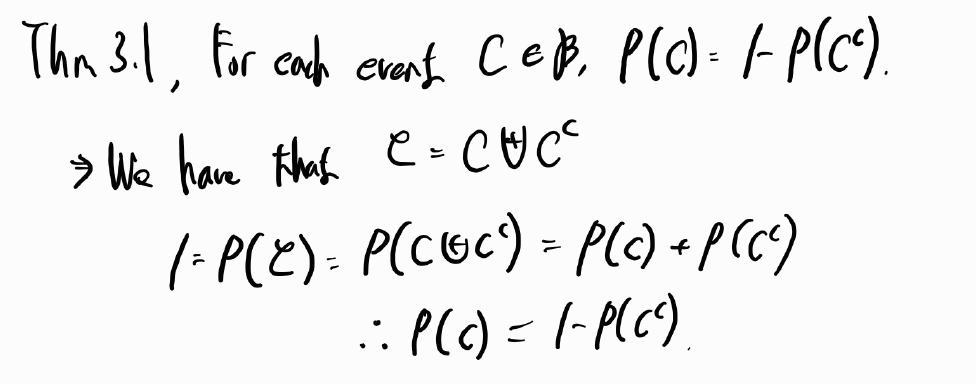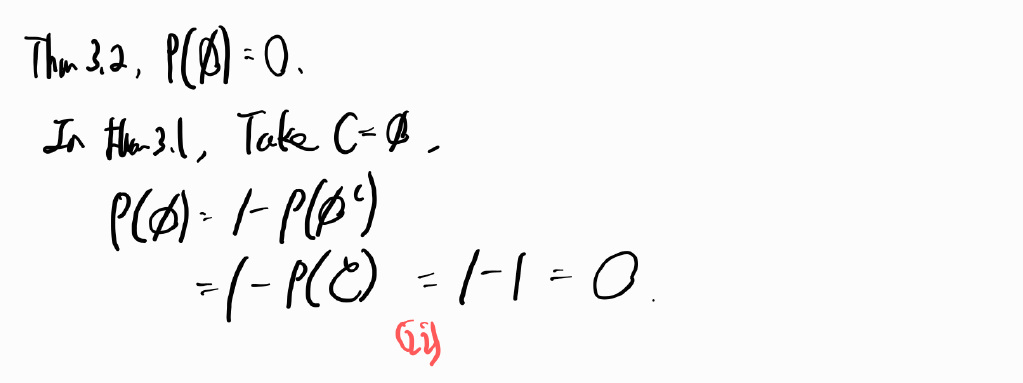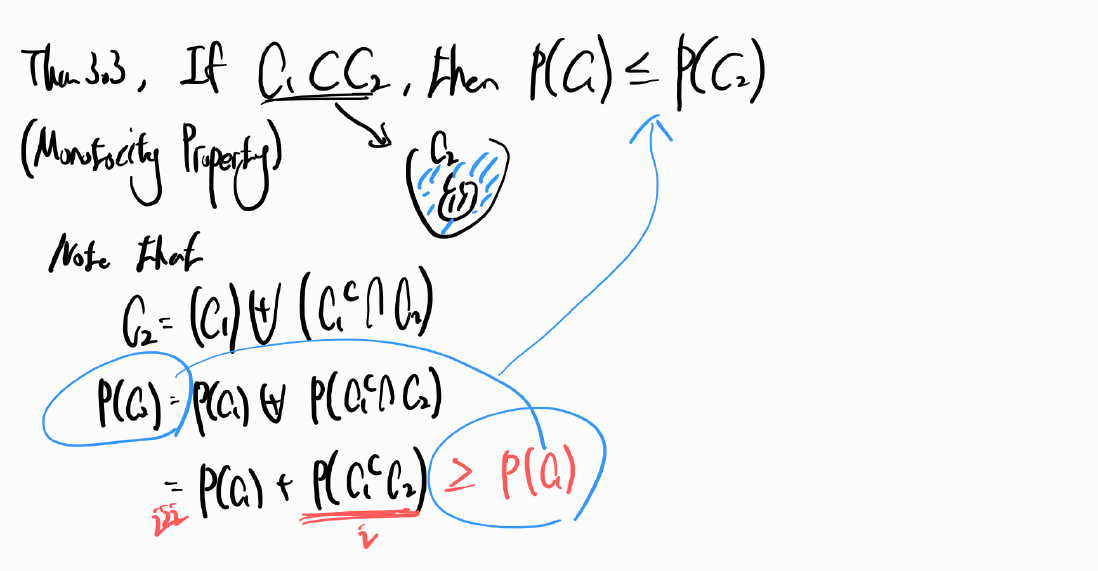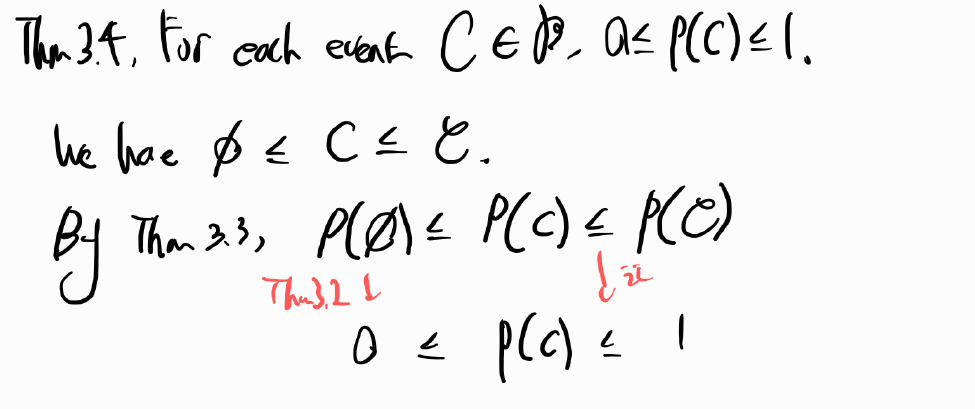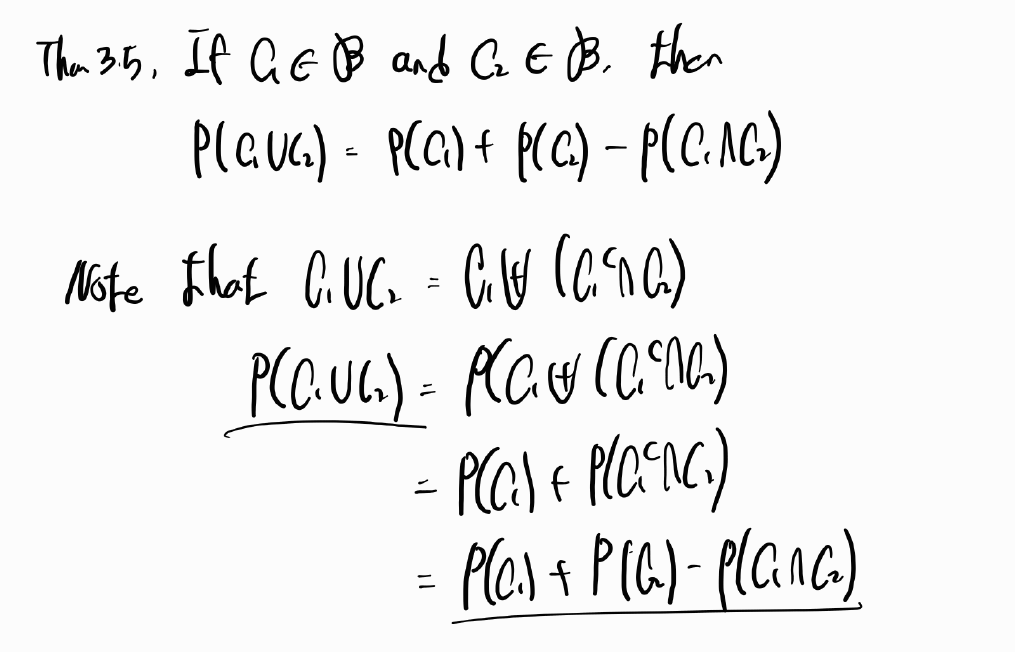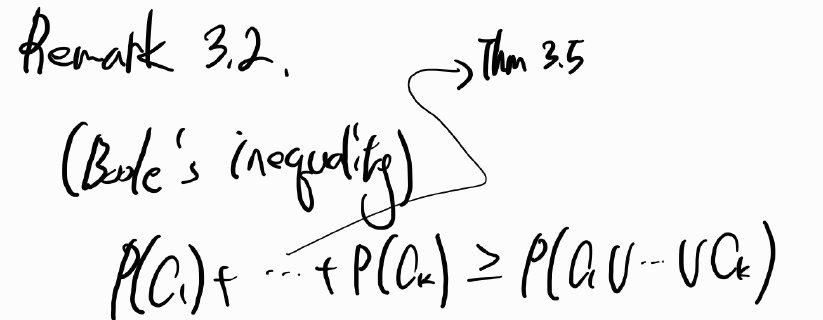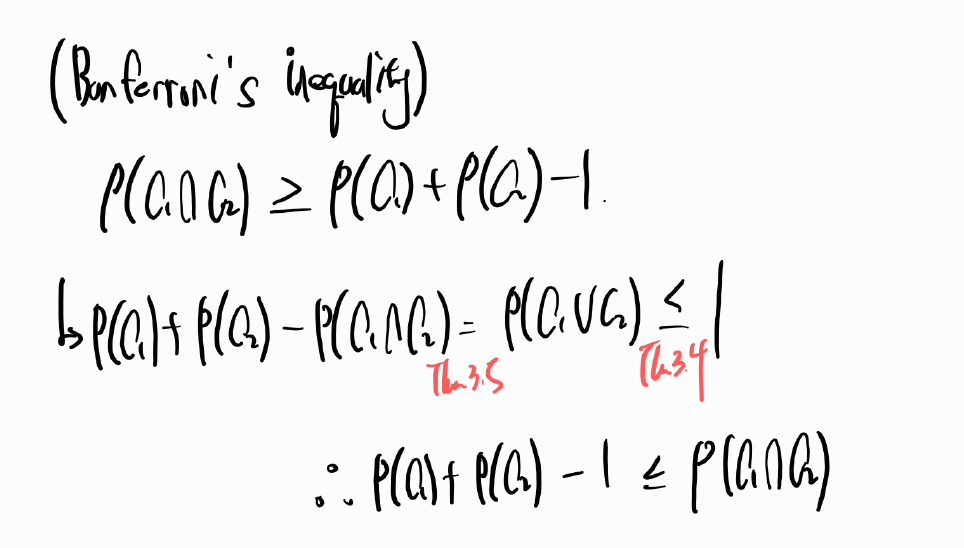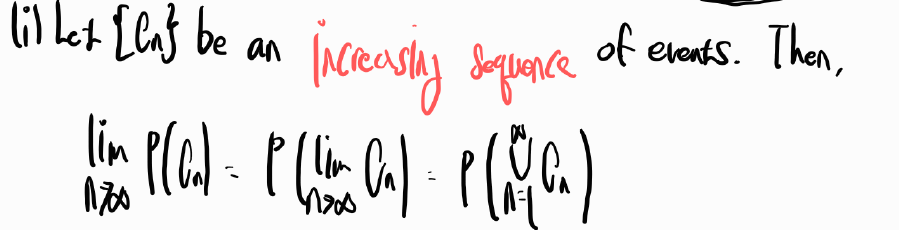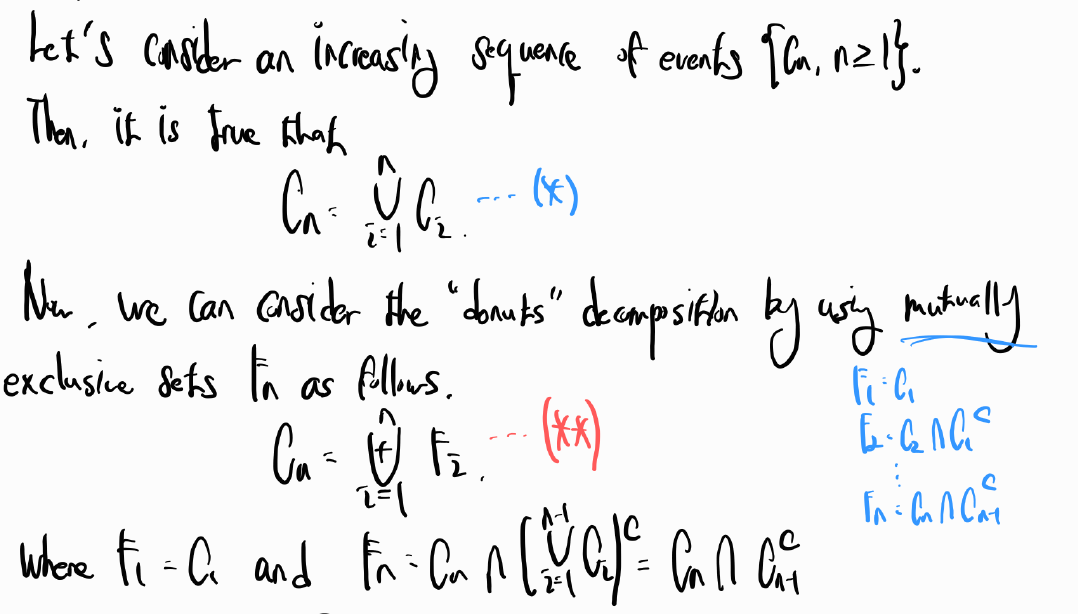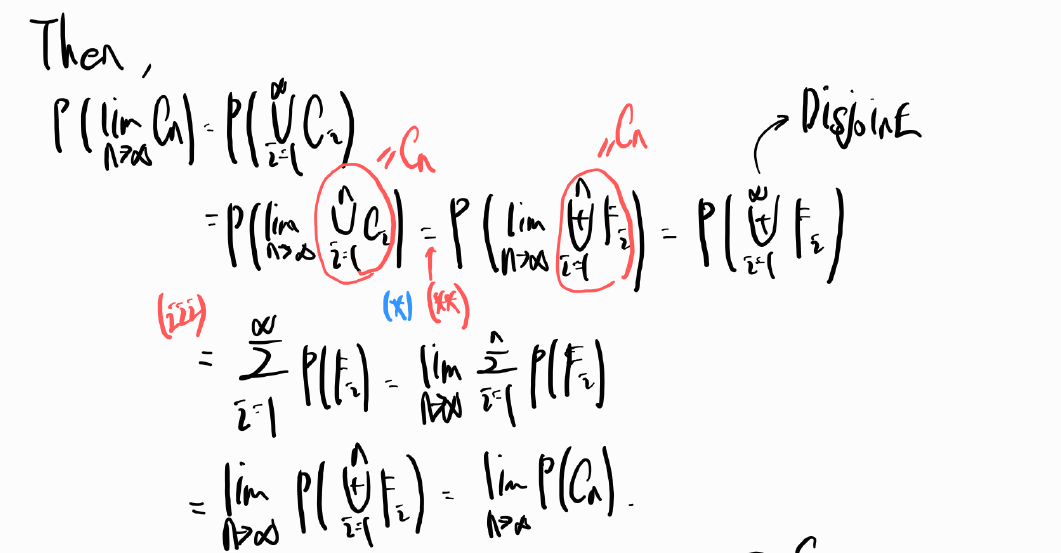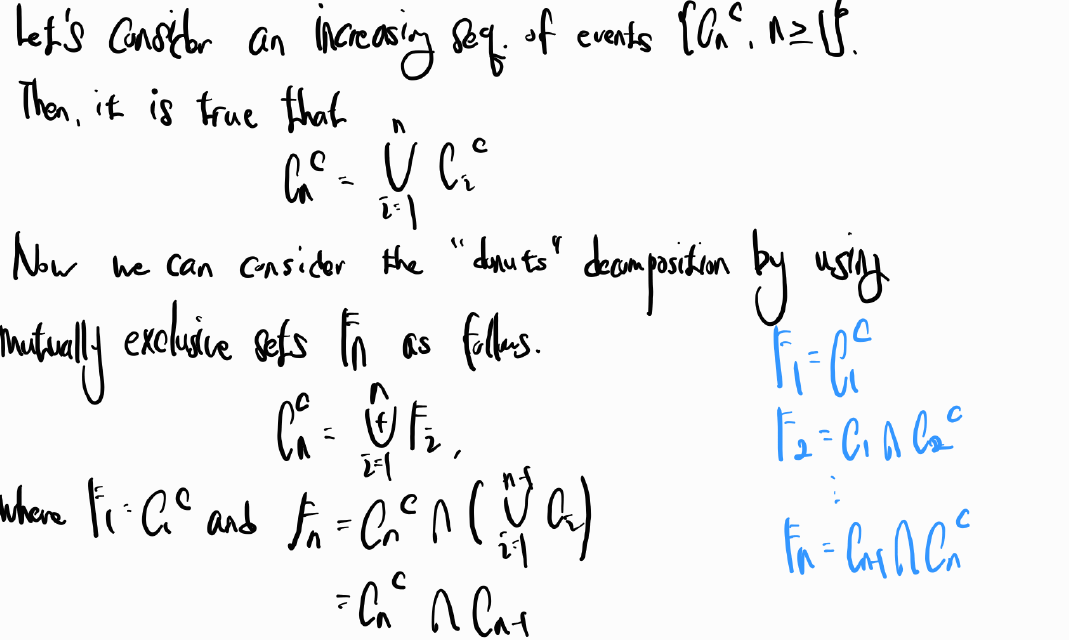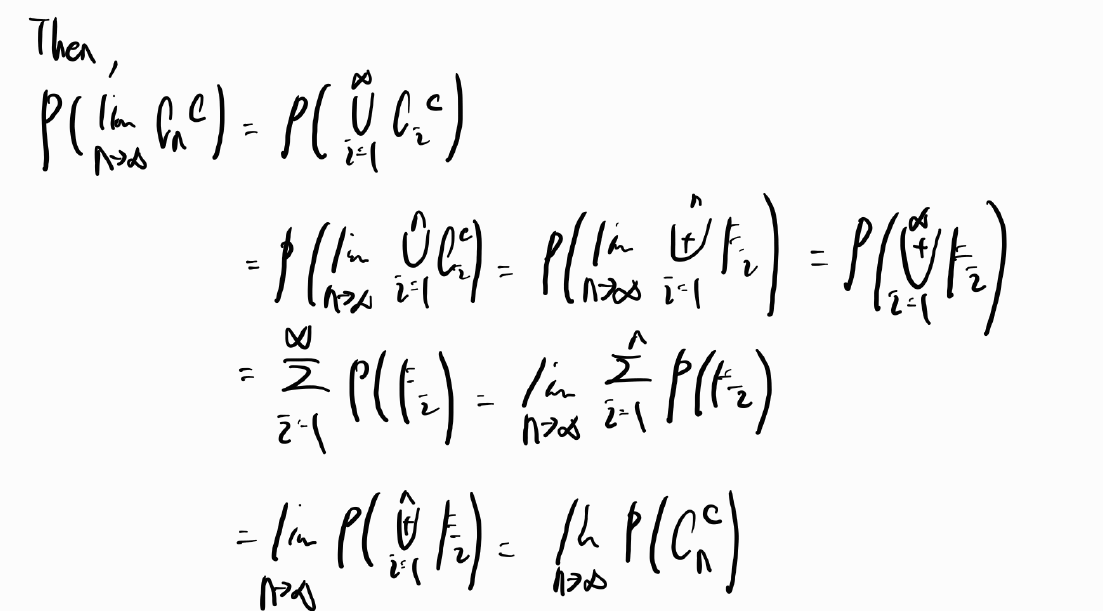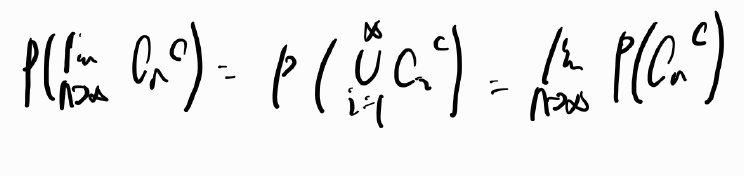The probability that C2 occurs given that event C1 has occurred is called the conditional probability of C2 given C1 and is defined by
그림으로 표현하자면 아래와 같다.
Conditional probability is a probability?
조건부확률이 확률의 정의를 만족하는지 살펴보자.
Properites of Conditional Probability
Ex. Four cards are to be dealt successively, at random and without replacement, from an ordinary deck of playing cards. The probability of receving a spade, a heart, a diamond, and a club, in that order is..
C1 : 1st - 13 / 52
C2 : 2nd - 13 / 51
C3 : 3rd - 13 / 50
C4 : 4th - 13 / 49
(카드 놀이에서 4번을 뽑는데 각각 다른 걸 뽑을 확률을 나타낸 것)
- Prior probability vs. posterior probability
- Let C1,...Ck : k causes of an event.
- P(Ci) indicates the chance of ith cause.
If known, it is obtained from the past investigation >>>> prior probability
(쉽게 말해 알려진 확률을 prior probability)
- P(Ci|C) indicates the chance of ith cause when the event C happened.
It updates the past information >>>> posterior probability
Independence
Statistically / stochastically independent means independent in a probability sense.
Two events A and B are independent if and only if P(A|B)=P(A|Bc)=P(A) or P(B|A)=P(B|Ac)=P(B). Otherwise, they are independent.
Events C1,C2,C3 are pairwise independents if and only if P(C1∩C2)=P(C1)P(C2), P(C1∩C3)=P(C1)P(C3), P(C2∩C3)=P(C2)P(C3).
Mutual Independence (모든 경우가 독립이면)
ex. Pairwise independence does not imply mutual independence
1,2,3,4가 적혀있는 spinner를 2번 돌렸다.
C1은 두 번 돌린 spinner의 숫자의 합이 5가 되는 사건이고, C2는 첫 번째 돌렸을 때 1이 나오면 되는 사건이고, C3는 두 번째 돌렸을 때 4가 나오면 되는 사건이다.
표를 통해서 모든 경우의 수를 생각해보면
1st \ 2nd
1
2
3
4
1
(1, 1)
(1, 2)
(1, 3)
(1, 4)
2
(2, 1)
(2, 2)
(2, 3)
(2, 4)
3
(3, 1)
(3, 2)
(3, 3)
(3, 4)
4
(4, 1)
(4, 2)
(4, 3)
(4, 4)
C1 > 빨간색
C2 > 파란색
C3 > 민트색
Then P(Ci)=1/4,i=1,2,3, and for i≠j, P(Ci∩Cj)=1/16.
Thus, C_1, C_2, C_3 are pairwise independent.
But, C1∩C2∩C3 is the event that (1, 4) is spun and its probability is 1/16.
P(C1∩C2∩C3)=1/4×1/4×1/4≠1/16
이것이 의미하는 것이 두 사건이 독립이라고 해서 mutual independence가 성립한다고 보장할 수 없다를 예제를 통해서 확인할 수 있다.
1. Find the smallest σ-field of subsets of C(체) = {1, 2, 3}.
2. Find the largest σ-field of subsets of C(체) = {1, 2, 3}.
Probability Space
Theorems
Remark
Thm 3.6. Continuity Property
위의 특징을 시각화하면 아래의 그림과 같다.
반드시 increasing sequence라는 조건이 있어야 한다.
증명을 해보면
파란색 별 모양이 의미하는 것이 Cn이 increasing sequence 중에서 가장 마지막에 나오는 집합이기에 앞서 나온 집합들을 다 포함할 수 있다는 것이다. 그러고 난 다음에 우리는 donut 모양으로 집합을 생각할 것인데 이것은 mutually exclusive의 성질을 사용하여 집합의 덧셈으로 표현하기 위함이다. 아래와 같이 표현할 수있다.
그러면 mutually exclusive 하기에 다음과 같이 표현이 가능하다.
decreasing sequence의 경우에도 같은 방향으로 살펴볼 수 있다. 그런데 이 때는 여집합을 사용해서 mutually exclusive한 성질을 사용하고자 한다.
- 어떤 Set C1의 모든 element가 C2의 element라면 Set C1 은 C2의 Subset이라고 한다.
∀x∈C1, x∈C2
Denoted by C_1 \subset C_2
Example
- Define two sets C1 = {(x, y) : 0 ≤x = y≤ 1} and C2 = {(x, y) : 0 ≤x≤ 1, 0 ≤y≤ 1}. Because the elements of C1 are the points on one diagonal of the square, then C1⊂C2.
- Remark: C1=C2 <=> C1⊂C2 & C2⊂C1
2. Intersection
- Intersection: C1∩C2 (= {x | x∈C1 and x∈C2})
집합이 유한개:
집합이 무한개:
- Null set: C=∅
If C1∩C2=∅, then C1 and C2 are said to be mutually exclusive or disjoint.
3. Union
- Union: C1∪C2 (= {x | x∈C1 or x∈C2})
- (Notation)
- 집합의 수에 따라 나눈 것(위: 유한개, 아래: 무한개)
4. Space and Complement
Space의 개념은 Basic concepts 참고
여기서 보면 Space의 표기가 다르다는 것을 확인할 수 있다. ('체'나 '데' 라고 부른다고 한다.)
- Any action or process by which observations (or measurements) are generated.
- The only way in which an investigator can elicit information about any phenomenon is to perform the experiments.
- Each experiment terminates with an outcome.
- If an experiment can be repeated under the same conditions, it is called a random experiment.
2. Sample space S (표본 공간 S)
- The sample space is a set that contains all possible outcomes of a particular experiment.
The number of outcomes in the sample space can be finite or infinite.
Infinite sample space can be countable or uncountable. A sample space is countable if the elements of the sample space can be put into 1-1 correspondence with a subset of the integers.
3. Event (사건)
- An event of a sample space S is a subset of S (including S itself).
A simple event contains only one outcome. Denoted by w.
A compound event contains two or more outcomes.
Experiment
Sample Space
Events
Tossing a coin
{H,T} : finite
∅, {H}, {T}, {H,T}
Rolling a dice
{1, 2, 3, 4, 5, 6} : finite
Observing the number of accidents at an intersection
{0, 1, 2, ...} : infinite - countable
Observing the survival time of a patient
{t : 0 < t} : infinite - uncountable
4. Probability (Relative Frequency Approach)
- Suppose that an experiment is performed N times.
- The relative frequency for an event A is AoccursN = fN.
- If we let N get infinitely large, P(A)=limN→∞fNN
LightGBM(Light Gradient Boosting Machine)은 Microsoft에서 개발한 고성능 그래디언트 부스팅 프레임워크입니다.
기존의 그래디언트 부스팅(Gradient Boosting)방법론을 개선하여 대규모 데이터셋에서도 빠른 학습과 예측을 제공하도록 설계되었습니다.
LightGBM은 특히 대규모 데이터와 복잡한 특징 공간을 가진 문제에서 빠른 처리 속도와 적은 메모리 사용을 강점으로 가집니다.
1 - 1. LightGBM의 역사
GBDT(Gradient Boosting Decision Tree)는 널리 사용되는 기계학습 알고리즘인데, 여러 효과적인 구현 중 하나가 XGBoost 모델입니다.
이 알고리즘은 특성 차원이 높을 때와 모든 가능한 분할 지점의 정보 이득을 추정해야 할 때 시간이 많이 소요되는 문제가 있습니다.
이를 극복하기 위해 LightGBM이 개발되었는데, Gradient-based One-side Sampling(GOSS)과 Exclusive Feature Bundling(EFB)과 같은 알고리즘을 사용했습니다.
이 알고리즘을 통해 전체 데이터셋의 일부만을 사용하여 각 트리를 훈련시킬 수 있으며, 고차원의 희소 특징을 효율적으로 처리할 수 있습니다.
2. LightGBM 특징 및 인기요인
LightGBM은 데이터의 개수가 적을 때(10000개 이하) 과적합이 발생할 수 있지만 다양한 장점 덕분에 자주 사용됩니다.
고속처리 및 효율성
LightGBM은 병렬 처리 및 데이터 샘플링 최적화를 통해 기존 그래디언트 부스팅 방식보다 훨씬 빠른 학습이 가능하게 합니다.
메모리 효율성을 통한 최적화
연속형 변수에 대해 구간을 만듦으로써 계산 과정에서 메모리 사용량을 줄입니다.
기존 방식에 비해 높은 처리 속도를 제공하며, 리소스가 제한적인 환경에서도 효율적으로 모델이 운용될 수 있도록 합니다.
결측치 자동 처리
별도의 결측치 처리 과정 없이도, 알고리즘은 결측치가 있는 데이터를 자동으로 인식하고 이를 학습 과정에 사용합니다.
범주형 변수 자동 처리
LightGBM은 범주형 변수를 효과적으로 처리할 수 있습니다.
자료형을 category로 바꾸어 주면 되며, 이외의 별도의 인코딩 과정이 필요하지 않습니다.
target = train['credit']
independent = train.drop(['index', 'credit'], axis = 1)
object_cols = [col for col in independent.columns if independent[col].dtype == "object"]
independent[object_cols] = independent[object_cols].astype('category')
위와 같은 형식으로 바꿔주는 작업을 거치면 됩니다.
스케일링 불필요
LightGBM은 트리 기반의 모델로서 입력 변수의 스케일에 민감하지 않습니다.
따라서 별도의 스케일링 작업 없이도 충분히 학습할 수 있습니다.
높은 정확도
LightGBM은 XGBoost와 비교하여 동등하거나 때때로 더 뛰어난 정확도를 제공합니다.
3. XGBoost 모델과의 차이
3.1 XGBoost란?
XGBoost(eXtreme Gradient Boosting)는 고성능 그래디언트 부스팅 라이브러리로, 정형 데이터 분석 대회에서 널리 사용되어 왔습니다.
XGBoost는 그래디언트 부스팅의 전통적인 방식을 발전시켜 특히 병렬 처리와 과적합 방지 기능에서 강력한 성능을 발휘합니다.
3.2 LightGBM vs XGBoost
XGBoost와 LightGBM은 모두 그래디언트 부스팅에 기반한 라이브러리이지만, 주요 차이점이 몇 가지 있습니다.
이들은 모두 데규모 데이터셋에서 뛰어난 성능을 제공하며, 병렬 처리 기능을 통해 훈련 속도를 향상시킵니다.
차이점1. 성장 방식
XGBoost는 Level-wise 방식을 사용하여 균형 잡힌 트리를 만들어 과적합을 방지하는 반면,
LightGBM은 Leaf-wise 방식을 사용하여 비대칭적인 트리를 빠르게 성장시킬 수 있습니다.
[Level-wise]
위의 이미지는 Level-wise 성장 방식을 나타낸 것입니다.
Level-wise 성장 방식에서는 모든 노드가 같은 레벨에 있을 때까지 자식 노드를 확장합니다.
Level-wise 성장 방식의 경우 트리가 균형 성장을 하면서 트리의 높이가 최소화되기 때문에 과적합 방지할 수 있다는 장점이 있지만, 많은 메모리를 사용한다는 단점이 있습니다.
[Leaf-wise]
반면, Leaf-wise 접근 방식은 트리의 성장을 최적화하여 가장 큰 손실 감소를 제공하는 노드를 우선적으로 확장합니다.
이 방법은 종종 더 깊은 트리를 만들어 과적합의 우려가 있지만, 적절하게 모델을 구성할 경우 과적합의 위험을 관리하면서도 정확한 모델을 빠르게 구축할 수 있습니다.
차이점2. 속도 및 대규모 데이터 처리
XGBoost는 병렬 처리 기능을 사용하여 동시에 트리를 구축하고 학습 속도를 향상시키는 능력이 있습니다.
그러나 이 과정에서 전체 데이터셋의 모든 특성을 스캔해야 하므로, 매우 큰 데이터셋의 경우 여전히 상당한 계산 비용과 시간이 소요될 수 있습니다.
LightGBM은 히스토그램 기반 분할 방식을 사용하여 이러한 계산 비용을 대폭 줄입니다.
이 방식에서 LightGBM은 데이터의 모든 연속형 변수를 미리 정의된 구간(bin)으로 변환하고, 이 구간 정보를 바탕으로 트리의 분할을 결정합니다.
이 방법은 데이터를 스캔하는 데 필요한 시간을 크게 줄이며, 메모리 사용도 최소화합니다.
차이점3. 범주형 변수 처리
XGBoost는 범주형 데이터를 처리하기 위해 라벨 인코딩, 원 핫 인코딩과 같이 수치형 데이터로 변환을 해야합니다.
반면, LightGBM은 범주형 변수의 자료형을 카테고리로 변환하기만 해도 학습이 가능합니다.
4. LightGBM 활용
LightGBM은 지도학습 라이브러리로, 주로 정형 데이터를 분석할 때 사용합니다.
5. LightGBM 세부설정
5.1. 주요 하이퍼파라미터
n_esitmators: 부스팅 단계의 횟수, 즉 모델이 생성할 트리의 수를 지정합니다. 해당 하이퍼파라미터의 값이 클수록 더 많은 트리를 모델에 추가하여 복잡한 데이터 패턴을 학습할 수 있으나, 높은 값은 과적합을 초래할 수 있습니다.
max_depth: 트리의 최대 깊이를 설정합니다. 깊이가 깊어질수록 모델은 더 복잡해지며, 과적합의 위험이 커집니다.
num_leaves: 트리가 가질 수 있는 리프 노드(말단 노드)의 수를 지정합니다. 리프 노드는 루트 노드(최상위 노드)와 내부 노드(분기 노드)를 제외한, 최종적인 결정이 이루어지는 노드를 의미합니다. 이 값이 크면 모델의 복잡도가 증가하여 예측 성능이 향상될 수 있지만, 너무 크면 과적합을 유발할 수 있습니다.
6. LightGBM 모델 학습 - 분류
6-1. 독립변수, 종속변수 설정 및 범주형 자료형 변환
종속변수(target)를 분리하고, 나머지 변수들을 독립변수(independent)로 사용합니다.
범주형 변수들은 LightGBM이 데이터를 처리할 수 있도록 category로 데이터 타입을 변환합니다. 이 변환은 문자열 변수를 인코딩 등의 방법을 이용하여 전처리하지 않는 한 LightGBM 모델을 사용하기 위해서는 필수적인 과정입니다.
target = train['credit']
independent = train.drop(['index', 'credit'], axis = 1)
object_cols = [col for col in independent.columns if independent[col].dtype == "object"]
independent[object_cols] = independent[object_cols].astype('category')
6-2. 학습/검증 데이터 설정
독립변수 independent와 종속변수 target을 학습과 검증 데이터로 분리합니다.
이후에는 학습 데이터로 LightGBM 모델을 학습시키고, 검증 데이터를 이용하여 각 시도에 대한 검증 점수를 확인하면 됩니다.
결측치 처리를 하지 않고 문자열 변수의 자료형을 category로만 설정하고, 인코딩과 같은 방법을 사용하지 않음에도 학습이 진행되는데 그 이유는 이 모델이 결측치와 범주형 변수를 자동으로 처리할 수 있는 기능이 있어, 모델 학습에서 별도의 전처리 없이도 학습이 가능합니다.
from lightgbm import LGBMClassifier
# LightGBM 모델 정의 및 학습
base_lgbm = LGBMClassifier(random_state = 42)
base_lgbm.fit(X_train, y_train)
# 검증점수 확인print("LGBM 모델 정확도:", base_lgbm.score(X_valid, y_valid))
6-4. 하이퍼파라미터 설정
from lightgbm.callback import early_stopping, log_evaluation
# LightGBM 모델 정의
tuning_lgbm = LGBMClassifier(n_estimators=300, max_depth=6, random_state = 42)
# 조기 종료와 학습 로그 출력 콜백 정의
early_stop = early_stopping(stopping_rounds=5)
# 조기 종료를 설정하는 부분이며,이 코드의 경우 5번의 부스팅 동안 성능 개선이 없을 때 종료합니다.
log_eval = log_evaluation(period=20)
## 모델 학습 과정에서 지정된 주기(20라운드)마다 평가지표를 출력합니다.# 모델 학습
tuning_lgbm.fit(
X_train, y_train,
eval_set=[(X_valid, y_valid)],
eval_metric='multi_logloss',
callbacks=[early_stop, log_eval]
)
# 정확도 출력print("하이퍼파라미터가 튜닝된 LGBM 모델 정확도:", tuning_lgbm.score(X_valid, y_valid))
6-5. 학습 과정의 성능 지표 모니터링
평가지표의 변화가 멈추거나, 특정 지점에서 성능이 개선되지 않는다면 과적합이 발생하거나 학습이 더 이상 효과적이지 않음을 의미할 수 있습니다. 이러한 경우 모델 학습 중 모니터링을 하면서 적절한 트리의 수가 얼마인지(n_estimators), 조기종료(early_stopping)를 해야할지 여부를 결정할 수 있습니다.
로그 손실(log loss)은 분류모델의 평가지표이며, 모델이 잘 예측을 수행할수록 낮은 값을 가집니다.
import lightgbm as lgb
import matplotlib.pyplot as plt
# 모델 학습 중 사용된 metric과 동일한 'multi_logloss'를 사용
loss_plot = lgb.plot_metric(tuning_lgbm.evals_result_, metric='multi_logloss')
## plot_metric 함수는 LightGBM의 학습 중에 기록된 평가지표를 시각화할 때 사용합니다. ## 각 반복마다 기록된 평가 지표는 evals_result_ 속성에 기록되는데,## 이 속성에는 지정된 검증 데이터셋에 대한 모델의 성능 평가 결과가 저장됩니다.## 이 코드를 실행함으로써 평가지표가 어떻게 변화하는지 확인할 수 있습니다.
plt.show()
plot_importance 함수는 모델 학습 중 각 피처의 중요도를 바 차트(bar chart)로 시각화하는 데 사용됩니다.
이 함수는 tuning_lgbm.booster_ 에서 제공하는 정보를 기반으로 작동합니다.
booster_ 속성은 LightGBM 모델의 부스터(Booster) 객체를 포함하고 있으며, 이는 모델이 생성한 결정 트리들의 집합입니다.
각 피처의 중요도는 이 결정 트리들 내에서 해당 피처가 얼마나 자주 사용되었는지를 통해 계산됩니다.
max_num_features 매개변수를 통해 표시되는 최대 피처의 수를 제한하여, 가장 중요도가 높은 피처만 시각화하도록 설정할 수 있습니다.
6-7. LightGBM 예측값
pred = tuning_lgbm.predict(X_valid)
logloss_pred = tuning_lgbm.predict(X_valid)
print(pred)
print('-'*40)
print(logloss_pred)
7. XGBoost와 학습 속도 비교
import pandas as pd
import time
from sklearn.model_selection import train_test_split
from lightgbm import LGBMClassifier
from xgboost import XGBClassifier
train = pd.read_csv('당뇨_train.csv')
target_col = 'Outcome'
target = train[target_col]
train = train.drop(['ID', target_col], axis = 1)
# 2. 학습 / 검증 데이터 분리
X_train, X_valid, y_train, y_valid = train_test_split(train, target, test_size=0.2, random_state=42)
# LightGBM 모델 학습
start_lgbm = time.time()
model_lgbm_classifier = LGBMClassifier(random_state = 42)
model_lgbm_classifier.fit(X_train, y_train)
end_lgbm = time.time()
# XGBoost 모델 학습
start_xgb = time.time()
model_xgb_classifier = XGBClassifier(random_state = 42)
model_xgb_classifier.fit(X_train, y_train)
end_xgb = time.time()
valid_score_lgbm_classifier = model_lgbm_classifier.score(X_valid, y_valid)
valid_score_xgb_classifier = model_xgb_classifier.score(X_valid, y_valid)
print("LGBM Classifier Validation Score:", valid_score_lgbm_classifier)
print("XGB Classifier Validation Score:", valid_score_xgb_classifier)
print("LGBM 모델의 학습 시간은", end_lgbm-start_lgbm,"초 입니다.")
print("XGB 모델의 학습 시간은", end_xgb-start_xgb,"초 입니다.")
8. LightGBM 모델 학습 - 회귀
8-1. 학습
from lightgbm.callback import early_stopping, log_evaluation
from lightgbm import LGBMRegressor
# LightGBM 모델 초기화
tuning_lgbm = LGBMRegressor(
n_estimators=300,
max_depth=8,
learning_rate= 0.01,
random_state = 42
)
# 조기 종료 및 학습 로그 출력 콜백 정의
early_stop = early_stopping(stopping_rounds=15)
log_eval = log_evaluation(period=20)
# 모델 학습
tuning_lgbm.fit(
X_train, y_train,
eval_set=[(X_valid, y_valid)],
eval_metric='rmse',
callbacks=[early_stop, log_eval]
)
# 정확도 출력print("LightGBM 회귀모델의 결정계수:", tuning_lgbm.score(X_valid, y_valid))
8-2. 평가지표 변화 추이 확인
import lightgbm as lgb
import matplotlib.pyplot as plt
# 모델 학습 중 사용된 metric과 동일한 'rmse'를 사용
loss_plot = lgb.plot_metric(tuning_lgbm.evals_result_, metric='rmse')
plt.show()
I work out every day for at least 2 hours to lose weight.
I read books to broaden my knowledge.
3. and, or, so, but, because
Take care and I'll call you later.
I couldn't sleep last night but I'm ok.
I should go home and rest because I'm so tired.
Conversation
What's your bucket list?
- Winning against professional basketball player by 1 on 1 is my bucket list. It's just a dream. :)
How do you release your stress?
- When I'm stressed, I feel like playing basketball.
What are the latest products you bought? Why did you buy them?
- I recently bought book to study machine learning.
What makes you study AI?
- This is just my opinion, I think if I don't study AI now, it seems like I will be hard to keep up with the speed of the future.
Why do we need to work?
- Work sometimes makes us tired. But, we can't live without work. Because everything around us is made by work of us.
Late at night, if you suddenly have something you want to do, what would it be?
- I feel like playing computer game late at night or drinking beer.
Why do people drink?
- This is not my opinion, it's my friend's opinion. He said if people were tired by physically exhausting, they find alcohol. However, if peoply were tired by mentally exhausting, they find beer. I think that's right.
She said I have to clean up my room every day, but I'm busy.
2. I have to / should + 동사
I have to find the answer by myself.
3. Sure, I can + 동사
Sure, I can go home by myself.
Sure, I can show you my bank balance.
Conversation
What did your parents nag you about?
- My father said you have to save money for your future.
How can you save the money?
- By investing in stocks, Installment savings.
May I ask how much you have?
- I can't tell you my assets, but I don't think I have much money.
What is the most important thing someone you like has ever said to you? Why do you like it?
- My father said "The higher you go, the lonelier you become. As you progress up the career ladder, things change dramatically. You will have far fewer colleagues; it gets increasingly lonely and there is much greater responsibility. The level of fear, uncertainity, and doubt will jump and so will stress levels. Hence, all the more reason why you should be a self-starter." I think he wanted me to be a person who could do anything on my own. What my father said was so impressive. It made me better person than before.
Whose words motivated you the most? What did they say?
- The mathematical analysis professor said "We need to do more and not be complacent now. "